Golang Memory Allocator
golang内存管理
go的内存管理是基于tcmalloc,这个连接看详情
盗来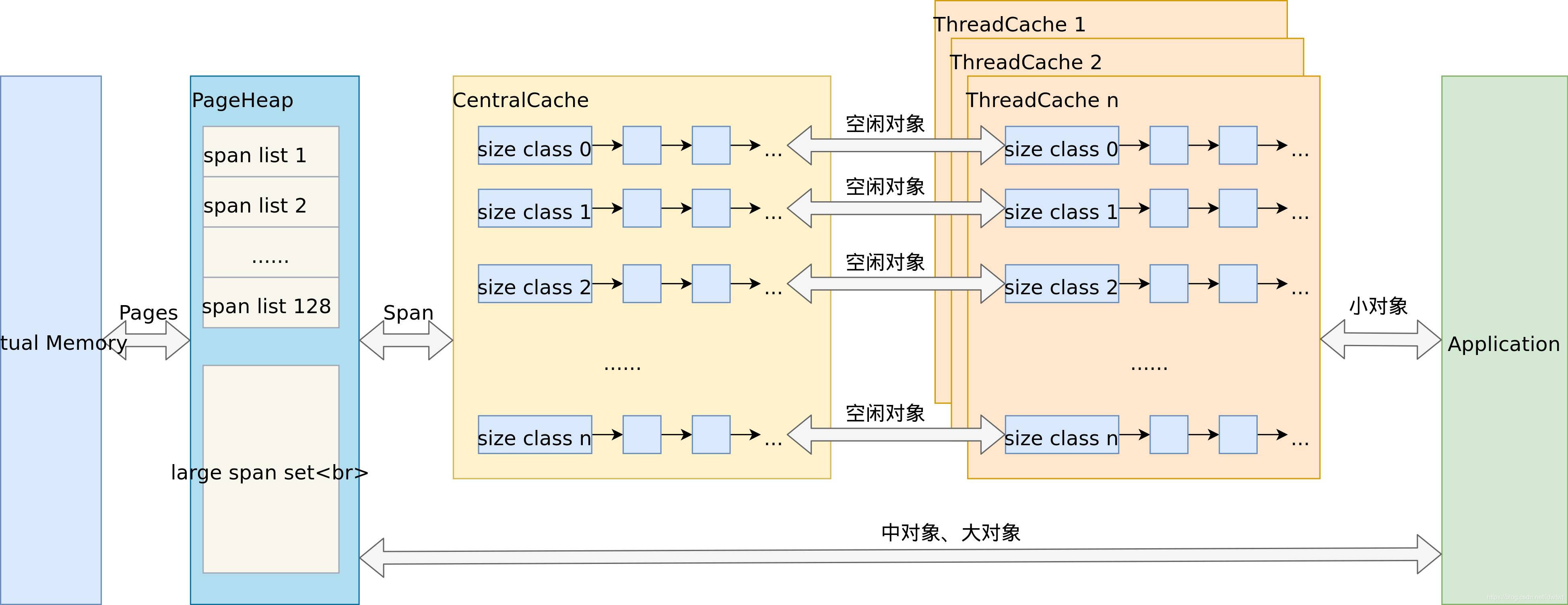
任何大小的内存页可以被分割成一系列同样大小的object,这些规定的大小size则被定义在sizetoclass,然后被一个bitmap管理
内存总体结构设计
暂时将linux amd64作为例子
虚拟内存布局
-
1.10以前,内存不是初始化就分配虚拟内存 arena大小为512G,为了方便将其分为一个个page,所以总共也有512G/8KB = 65536个page
span区域存放指向span的指针,表示arena区域page所属的span,所以其大小即为 512GB/8KB* 8B(指针大小) = 512M
bitmap主要用于GC,两个bit表示arena中一个字的可用状态,所以表示为 (512GB/ 8(8个byte一个字,即指令长度)) * 2 /8 (8个bit一个byte) = 16G 长度
-
1.11以后
改成两阶段稀疏索引方式,内存允许超过512G,也可以允许不连续内存 mheap中的arenas字段实际是一个指针数组,每个
heapArena管理一个64MB的内存 其结构如下:
//// heapArenaBitmapBytes is the size of each heap arena's bitmap.
heapArenaBitmapBytes = heapArenaBytes / (sys.PtrSize * 8 / 2)
pagesPerArena = heapArenaBytes / pageSize
// A heapArena stores metadata for a heap arena. heapArenas are stored
// outside of the Go heap and accessed via the mheap_.arenas index.
//
//go:notinheap
type heapArena struct {
// bitmap stores the pointer/scalar bitmap for the words in
// this arena. See mbitmap.go for a description. Use the
// heapBits type to access this.
//即是内存中bitmap对应
bitmap [heapArenaBitmapBytes]byte
// spans maps from virtual address page ID within this arena to *mspan.
// For allocated spans, their pages map to the span itself.
// For free spans, only the lowest and highest pages map to the span itself.
// Internal pages map to an arbitrary span.
// For pages that have never been allocated, spans entries are nil.
//
// Modifications are protected by mheap.lock. Reads can be
// performed without locking, but ONLY from indexes that are
// known to contain in-use or stack spans. This means there
// must not be a safe-point between establishing that an
// address is live and looking it up in the spans array.
//这里的safe-point一般就指STW和栈扫描时期
//与内存中spans对应
spans [pagesPerArena]*mspan
// pageInUse is a bitmap that indicates which spans are in
// state mSpanInUse. This bitmap is indexed by page number,
// but only the bit corresponding to the first page in each
// span is used.
//
// Reads and writes are atomic.
pageInUse [pagesPerArena / 8]uint8
// pageMarks is a bitmap that indicates which spans have any
// marked objects on them. Like pageInUse, only the bit
// corresponding to the first page in each span is used.
//
// Writes are done atomically during marking. Reads are
// non-atomic and lock-free since they only occur during
// sweeping (and hence never race with writes).
//
// This is used to quickly find whole spans that can be freed.
//
// TODO(austin): It would be nice if this was uint64 for
// faster scanning, but we don't have 64-bit atomic bit
// operations.
pageMarks [pagesPerArena / 8]uint8
// zeroedBase marks the first byte of the first page in this
// arena which hasn't been used yet and is therefore already
// zero. zeroedBase is relative to the arena base.
// Increases monotonically until it hits heapArenaBytes.
//
// This field is sufficient to determine if an allocation
// needs to be zeroed because the page allocator follows an
// address-ordered first-fit policy.
//
// Read atomically and written with an atomic CAS.
//字段指向了该结构体管理的内存的基地址
//很多在堆上的零值都是指向了这里
zeroedBase uintptr
}bitmap和spans功能不变
基本内存管理级别
类似于TCMalloc
大概概括: 其目的是 减少多线程对内存请求时候的锁竞争,在对小内存的申请时甚至可以无锁操作,获取大内存时用spinlocks;但是其在TLS会预分配一部分空间,所以启动时相比dlmalloc等其他内存分配器空间较大,但是最终会接近;
class_to_allocnpages总共有67???个范围(应该是程序经过测试得来的数值)
栈的分配也是多层次和多class的
mspan (主要使用该机制减少碎片):
基本单元内存单元 被内存堆管理的的页面,至少一个页(8KB),用于范围分配内存,比如16-32B则分配32B,112~128则分配128B的span
type mspan struct {
//实际是一个doubly-linked lilst
next *mspan // next span in list, or nil if none
prev *mspan // previous span in list, or nil if none
list *mSpanList // For debugging. TODO: Remove.
startAddr uintptr // address of first byte of span aka s.base()
npages uintptr // number of pages in span
manualFreeList gclinkptr // list of free objects in mSpanManual spans
// freeindex is the slot index between 0 and nelems at which to begin scanning
// for the next free object in this span.
// Each allocation scans allocBits starting at freeindex until it encounters a 0
// indicating a free object. freeindex is then adjusted so that subsequent scans begin
// just past the newly discovered free object.
//
// If freeindex == nelem, this span has no free objects.
//
// allocBits is a bitmap of objects in this span.
// If n >= freeindex and allocBits[n/8] & (1<<(n%8)) is 0
//???为什么这样计算
// then object n is free;
// otherwise, object n is allocated. Bits starting at nelem are
// undefined and should never be referenced.
//
// Object n starts at address n*elemsize + (start << pageShift).
freeindex uintptr
// TODO: Look up nelems from sizeclass and remove this field if it
// helps performance.
nelems uintptr // number of object in the span.
// Cache of the allocBits at freeindex. allocCache is shifted
// such that the lowest bit corresponds to the bit freeindex.
// allocCache holds the complement of allocBits, thus allowing
// ctz (count trailing zero) to use it directly.
// allocCache may contain bits beyond s.nelems; the caller must ignore
// these.
//- allocBits在freeIndex上的缓存;
//- allocBits的补码,ctz可以直接使用来计算查找空闲的内存;
//- 会包含一些s.nelems前面的位,调用者要忽略这些位;
//在mspan.refillAllocCache()时改变值;
allocCache uint64
// allocBits and gcmarkBits hold pointers to a span's mark and
// allocation bits. The pointers are 8 byte aligned.
// There are three arenas where this data is held.
// free: Dirty arenas that are no longer accessed
// and can be reused.
// next: Holds information to be used in the next GC cycle.
// current: Information being used during this GC cycle.
// previous: Information being used during the last GC cycle.
// A new GC cycle starts with the call to finishsweep_m.
// finishsweep_m moves the previous arena to the free arena,
// the current arena to the previous arena, and
// the next arena to the current arena.
// The next arena is populated as the spans request
// memory to hold gcmarkBits for the next GC cycle as well
// as allocBits for newly allocated spans.
//
// The pointer arithmetic is done "by hand" instead of using
// arrays to avoid bounds checks along critical performance
// paths.
// The sweep will free the old allocBits and set allocBits to the
// gcmarkBits. The gcmarkBits are replaced with a fresh zeroed
// out memory.
allocBits *gcBits
gcmarkBits *gcBits
// sweep generation:
// if sweepgen == h->sweepgen - 2, the span needs sweeping
// if sweepgen == h->sweepgen - 1, the span is currently being swept
// if sweepgen == h->sweepgen, the span is swept and ready to use
// if sweepgen == h->sweepgen + 1, the span was cached before sweep began and is still cached, and needs sweeping
// if sweepgen == h->sweepgen + 3, the span was swept and then cached and is still cached
// h->sweepgen is incremented by 2 after every GC
//sweepgen 的分代,用于垃圾回收,与
sweepgen uint32
divMul uint16 // for divide by elemsize - divMagic.mul
baseMask uint16 // if non-0, elemsize is a power of 2, & this will get object allocation base
allocCount uint16 // number of allocated objects
spanclass spanClass // size class and noscan (uint8)
//管理状态
state mSpanState // mspaninuse etc
needzero uint8 // needs to be zeroed before allocation
divShift uint8 // for divide by elemsize - divMagic.shift
divShift2 uint8 // for divide by elemsize - divMagic.shift2
scavenged bool // whether this span has had its pages released to the OS
elemsize uintptr // computed from sizeclass or from npages
limit uintptr // end of data in span
speciallock mutex // guards specials list
specials *special // linked list of special records sorted by offset.
}主要的字段:
-
startAddr和npages确定结构体管理的多个页所在的内存,每个页都是8KB -
elementsize: slot大小,Byte为单位 -
freeindex,<该值的已经被分配,>=该位置的可能未被分配,需要配合allocCache查找,每次分配后,freeindex设置为分配的slot+1,用作扫描野种空闲对象的初始索引; -
allocBits标记内存占用状态,表示上一次GC之后哪一些slot被使用,0未使用或释放,1已分配 -
gcmarkBits标记内存回收状态 -
每次gc完的sweep阶段,将
allocBits设置为gcmarkbits -
allocCache是allocBits的表示从freeindex开始的64个slot的分配情况,1为未分配,0为已分配,使用ctz(Count trailing zeros指令)找到第一个非0位,使用完了就从allocBits加载,取反; -
sweepgen,垃圾回收的分代状态,主要拥有同mheap中的当前mSpan的sweepgen进行比较:每次GC,
h->sweepgen都会 +2 ;- 如果 sweepgen == h->sweepgen - 2, 这个span需要清除
- 如果 sweepgen == h->sweepgen - 1, 这个span正在被清除
- if sweepgen == h->sweepgen, 这个span已经被清除过并且就绪可用
- if sweepgen == h->sweepgen + 1, 这个span在清除之前就被缓存且仍在缓存中,需要被清除(很明显这里mSpan的sweepgen>h.sweepgen,证明已经活过了上一次清除,即被缓存下来);
- if sweepgen == h->sweepgen + 3, 这个span被清除后缓存,且在缓存中(一般来讲是不需要再缓存了???)
管理结构
-
当结构体管理内存不足时
其会以
页为单位向堆申请内存, 涉及npages字段 -
当用户程序或者线程向
mspan申请内存时该结构会使用
allocCache字段以对象为单位在管理的内存中快速查找待分配的空间,
如果找得到就返回,如果找不到,更上一级的mcache会调用mcache.refill更新内存管理单元mspan满足需求
状态
结构体下面的
mSpanStateBox 会用来存储mSpan的状态
type mSpan struct{
...
state mSpanStateBox
...
}
// An mspan representing actual memory has state mSpanInUse,
// mSpanManual, or mSpanFree. Transitions between these states are
// constrained as follows:
//
// * A span may transition from free to in-use or manual during any GC
// phase.
//
// * During sweeping (gcphase == _GCoff), a span may transition from
// in-use to free (as a result of sweeping) or manual to free (as a
// result of stacks being freed).
//
// * During GC (gcphase != _GCoff), a span *must not* transition from
// manual or in-use to free. Because concurrent GC may read a pointer
// and then look up its span, the span state must be monotonic.
//
// Setting mspan.state to mSpanInUse or mSpanManual must be done
// atomically and only after all other span fields are valid.
// Likewise, if inspecting a span is contingent on it being
// mSpanInUse, the state should be loaded atomically and checked
// before depending on other fields. This allows the garbage collector
// to safely deal with potentially invalid pointers, since resolving
// such pointers may race with a span being allocated.
type mSpanState uint8
const (
mSpanDead mSpanState = iota
mSpanInUse // allocated for garbage collected heap
mSpanManual // allocated for manual management (e.g., stack allocator)
)里面一大段注释其实差不多讲明了状态转换:
- 当
mspan在空闲的堆中,就会处于mspanFree状态 - 当
mspan已经被分配,就会处于mspanInUse,mSpanMannual状态,其转换有:- gc的任何阶段,可能从
mSpanFree转到mSpanInUse,mSpanMannual - gc的清除阶段,可能从
mSpanInUse转到mSpanMannual,mSpanFree - gc的标记阶段,可能从
mSpanInUse转到mSpanMannual,mSpanFree
- gc的任何阶段,可能从
其状态转换还一定要是原子操作,避免竞态条件
spanClass
spanClass
type mSpan struct{
...
spanClass spanClass
...
}
// A spanClass represents the size class and noscan-ness of a span.
//
// Each size class has a noscan spanClass and a scan spanClass. The
// noscan spanClass contains only noscan objects, which do not contain
// pointers and thus do not need to be scanned by the garbage
// collector.
//前7位存其ID,最后一位是noscan位
type spanClass uint8这个是mSpan的跨度类,决定了内存管理单元的存储对象大小和数量,
-
有67种,在
class_to_size和class_to_allocnpages上,参照下面补全的表格 -
其除了保存类别的ID(前7位),还会保存
noscan标记位(最后一位),这个标记了对象是否包含指针,gc会对无该标记位的mspan扫描
以下的函数为ID和标记位的保存方式:
func makeSpanClass(sizeclass uint8, noscan bool) spanClass{
return spanClass(sizeclass<<1) | spanClass(bool2int(noscan))
}func (sc spanClass) sizeclass() int8 {
return int8(sc >> 1)
}func (sc spanClass) noscan() bool {
return sc&1 != 0
}mcache
主要用来缓存小对象(0~32KB),里面就有基本单元mspan, 与线程上的处理器一一绑定;
- 多层次的cache用来减少分配冲突,
mcache是per-P的,所以无锁;小于16B直接使用P中的macache???
每一个mcache都有672*个mspan结构,都在alloc字段中;
- 其初始化的时候不包含
mspan,只有当用户申请内存才会从上一级mspan来满足要求
结构
// Per-thread (in Go, per-P) cache for small objects.
// No locking needed because it is per-thread (per-P).
//
// mcaches are allocated from non-GC'd memory, so any heap pointers
// must be specially handled.
//
//因为只用作local P,所以自然无锁
//go:notinheap
//这个标志说明了不在heap中,也可以理解,per - P好明显不在公共heap中
type mcache struct {
// The following members are accessed on every malloc,
// so they are grouped here for better caching.
next_sample uintptr // trigger heap sample after allocating this many bytes
local_scan uintptr // bytes of scannable heap allocated
// Allocator cache for tiny objects w/o pointers.
// See "Tiny allocator" comment in malloc.go.
//具体可以见下面的tiny allocator分配器
// tiny points to the beginning of the current tiny block, or
// nil if there is no current tiny block.
//
// tiny is a heap pointer. Since mcache is in non-GC'd memory,
// we handle it by clearing it in releaseAll during mark
// termination.
tiny uintptr
tinyoffset uintptr
local_tinyallocs uintptr // number of tiny allocs not counted in other stats
// The rest is not accessed on every malloc.
//都保存在这里,67*2个
alloc [numSpanClasses]*mspan // spans to allocate from, indexed by spanClass
stackcache [_NumStackOrders]stackfreelist
// Local allocator stats, flushed during GC.
local_largefree uintptr // bytes freed for large objects (>maxsmallsize)
local_nlargefree uintptr // number of frees for large objects (>maxsmallsize)
local_nsmallfree [_NumSizeClasses]uintptr // number of frees for small objects (<=maxsmallsize)
// flushGen indicates the sweepgen during which this mcache
// was last flushed. If flushGen != mheap_.sweepgen, the spans
// in this mcache are stale and need to the flushed so they
// can be swept. This is done in acquirep.
//用作标记该mcache在最后一次写入磁盘的sweep状态
//如果其不等于mheap中的sweepgen,证明该mcahce内的spans都是稳定的且需要被写入磁盘,所以可以被清除;
//整个过程在acquirep中完成;
flushGen uint32
}初始化
如下代码所示,实际会在systemstack中使用mheap的mcache分配器分配新的mcache
func allocmcache() *mcache {
var c *mcache
systemstack(func() {
lock(&mheap_.lock)
c = (*mcache)(mheap_.cachealloc.alloc())
//让flushGen设为mheap的sweepgen,未稳定,所以不可以被清除;
c.flushGen = mheap_.sweepgen
unlock(&mheap_.lock)
})
for i := range c.alloc {
//每个元素只是一个emptySpan占位符;
c.alloc[i] = &emptymspan
}
c.next_sample = nextSample()
return c
}替换已有的mspan
mcache.refill方法会使mcache获取一个指定的spanClass(从下一级mcentral中),被替换的mSpan不可以有空闲的内存空间(否则可能会频繁替换),
而获取的mspan中需要至少包含一个空闲对象用于分配内存;
// refill acquires a new span of span class spc for c. This span will
// have at least one free object. The current span in c must be full.
//
// Must run in a non-preemptible context since otherwise the owner of
// c could change.
func (c *mcache) refill(spc spanClass) {
// Return the current cached span to the central lists.
s := c.alloc[spc]
//allocCount必须要=nelems判断span的空间已经被用完
if uintptr(s.allocCount) != s.nelems {
throw("refill of span with free space remaining")
}
if s != &emptymspan {
// Mark this span as no longer cached.
if s.sweepgen != mheap_.sweepgen+3 {
throw("bad sweepgen in refill")
}
//标记该mSpan=mheap.sweepgen+3, 即不需要再缓存???
atomic.Store(&s.sweepgen, mheap_.sweepgen)
}
// Get a new cached span from the central lists.
//从mcentral取的mSpan
s = mheap_.central[spc].mcentral.cacheSpan()
if s == nil {
throw("out of memory")
}
//判断取来的mSpan是不是已经无空余空间了
if uintptr(s.allocCount) == s.nelems {
throw("span has no free space")
}
// Indicate that this span is cached and prevent asynchronous
// sweeping in the next sweep phase.
s.sweepgen = mheap_.sweepgen + 3
}注意这个是向mcache插入mSpan的唯一方法(上一级是nextFree函数,在mallocgc上被使用);
分配超小(tiny)对象(<16KB)的字段
mcache还对微小对象进行了分配处理:
type mcache struct {
....
tiny uintptr
tinyoffset uintptr
local_tinyallocs uintptr
....
}其中要注意:
- tinyAllocator只分配非指针类型的内存
tiny指向堆中的一块内存,tinyOffset是下一个空闲内存的offset,localtinyallocs会记录内存分配器中分配的对象个数
可以见下面的分配器
mcentral
可以看做是一种缓存(mcache的下一级),但内存管理单元mspan不存在空闲对象时,程序就会从这个缓存中拿新的内存单元;
与mcache不同,该结构的mSpan需要加锁访问(非per-P);
全局有 67 × 2 (指针的有67,非指针的有67) 个对应不同size的span 后备mcentral
收集所有特定size的span,如果也被用完,则再次转向mheap申请(这个mcentral其实就是属于mheap的,其都会直接从系统中申请内存)
结构体
type mcentral struct {
//加锁
lock mutex
spanclass spanClass
//管理包含空闲对象的mSpan list
nonempty mSpanList // list of spans with a free object, ie a nonempty free list
//不包含空闲对象对象或者是在mcache中缓存的mSpan list
empty mSpanList // list of spans with no free objects (or cached in an mcache)
// nmalloc is the cumulative count of objects allocated from
// this mcentral, assuming all spans in mcaches are
// fully-allocated. Written atomically, read under STW.
nmalloc uint64
}可以看到mcentral有两个mSpanList,分别是包含空闲对象的链表和不包含空闲对象的链表;
初始化时两个链表都不包含任何内存,扩容时nmalloc会记录分配的对象个数,写入该值时是用atomic写入,读取因为是在STW中,所以无锁(这个很像mSpan中???);
type mheap struct{
...
// central free lists for small size classes.
// the padding makes sure that the mcentrals are
// spaced CacheLinePadSize bytes apart, so that each mcentral.lock
// gets its own cache line.
// central is indexed by spanClass.
//numSpanClasses = _NumSizeClasses << 1 = 134
central [numSpanClasses]struct {
mcentral mcentral
pad [cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize]byte
}
....
}代码中的pad是用作分割多个mcentral,以CacheLinePadSize个Bytes分割开,所以每一个mcentral的lock可以得到自己的cache line
我认为可以看做是内存对齐的一种方法(???是不是捏,是的,为了不同列表间互斥锁不会伪共享)
获得mSpan
mcache会通过mcentral.cacheSpan方法获取新的内存管理单元mSpan:
可以大致分为几个步骤:
-
从有空闲对象的
mSpan链表获取可以使用的内存管理单元; -
从没有空闲对象的
mSpan链表中查找可以使用的内存管理单元; -
调用
mcentral.grow从堆中申请新的内存管理单元; -
更新内存管理单元的
allocCache等字段帮助快速分配内存;
func (c *mcentral) cacheSpan() *mspan {
// Deduct credit for this span allocation and sweep if necessary.
spanBytes := uintptr(class_to_allocnpages[c.spanclass.sizeclass()]) * _PageSize
deductSweepCredit(spanBytes, 0)
lock(&c.lock)
traceDone := false
if trace.enabled {
traceGCSweepStart()
}
//mheap中的sweepgen
sg := mheap_.sweepgen
retry:
var s *mspan
//从nonempty的list一一取出mSpan,判断其sweepgen
for s = c.nonempty.first; s != nil; s = s.next {
//1. mSpan等待回收状态(mspan.sweepgen = h.sweepgen-2)
if s.sweepgen == sg-2 && atomic.Cas(&s.sweepgen, sg-2, sg-1) {
//从nonempty中移除,因为是等待回收了,就肯定是属于空闲链表;
c.nonempty.remove(s)
//插入empty链表
c.empty.insertBack(s)
unlock(&c.lock)
//并且清理该mSpan
s.sweep(true)
goto havespan
}
//2. mspan.sweepgen=h.sweepgen-1, 正在被清除
if s.sweepgen == sg-1 {
// the span is being swept by background sweeper, skip
continue
}
//3. mspan已经被清除
// we have a nonempty span that does not require sweeping, allocate from it
c.nonempty.remove(s)
c.empty.insertBack(s)
unlock(&c.lock)
goto havespan
}
....
}接下来如果mcentral没在nonemtpy中找到可用的mSpan,会继续遍历其empty链表,处理几乎一样(可以注意一下用到了freeIndex来快速判断有无可用mSpan);
func (c *mcentral) cacheSpan() *mspan {
...
retry:
...
for s = c.empty.first; s != nil; s = s.next {
if s.sweepgen == sg-2 && atomic.Cas(&s.sweepgen, sg-2, sg-1) {
// we have an empty span that requires sweeping,
// sweep it and see if we can free some space in it
c.empty.remove(s)
// swept spans are at the end of the list
c.empty.insertBack(s)
unlock(&c.lock)
s.sweep(true)
freeIndex := s.nextFreeIndex()
if freeIndex != s.nelems {
s.freeindex = freeIndex
goto havespan
}
lock(&c.lock)
// the span is still empty after sweep
// it is already in the empty list, so just retry
goto retry
}
if s.sweepgen == sg-1 {
// the span is being swept by background sweeper, skip
continue
}
// already swept empty span,
// all subsequent ones must also be either swept or in process of sweeping
break
}
...
}如果在nonempty和empty都找不到可用的mSpan,就会触发申请内存c.grow;
最后只要有申请到可用的mSpan进入HaveSpan中,都会对allocCache,allocBits等字段进行更新;
func (c *mcentral) cacheSpan() *mspan {
...
retry:
...
if trace.enabled {
traceGCSweepDone()
traceDone = true
}
unlock(&c.lock)
// Replenish central list if empty.
//申请内存
s = c.grow()
if s == nil {
return nil
}
lock(&c.lock)
//将其放入到empty链表中
c.empty.insertBack(s)
unlock(&c.lock)
// At this point s is a non-empty span, queued at the end of the empty list,
// c is unlocked.
havespan:
if trace.enabled && !traceDone {
traceGCSweepDone()
}
n := int(s.nelems) - int(s.allocCount)
if n == 0 || s.freeindex == s.nelems || uintptr(s.allocCount) == s.nelems {
throw("span has no free objects")
}
// Assume all objects from this span will be allocated in the
// mcache. If it gets uncached, we'll adjust this.
atomic.Xadd64(&c.nmalloc, int64(n))
usedBytes := uintptr(s.allocCount) * s.elemsize
atomic.Xadd64(&memstats.heap_live, int64(spanBytes)-int64(usedBytes))
if trace.enabled {
// heap_live changed.
traceHeapAlloc()
}
if gcBlackenEnabled != 0 {
// heap_live changed.
gcController.revise()
}
freeByteBase := s.freeindex &^ (64 - 1)
whichByte := freeByteBase / 8
// Init alloc bits cache.
s.refillAllocCache(whichByte)
// Adjust the allocCache so that s.freeindex corresponds to the low bit in
// s.allocCache.
s.allocCache >>= s.freeindex % 64
return s
}mcentral.grow()方法如下:
- 会根据预先分配的
class_to_allocnpages和class_to_size进行分配page或者spanClass对应的size; - 并且调用
mheap.alloc获取新的mSpan - 获取
mSpan后,会初始化mSpan.liimt字段,并清除在mheap上的bitmap
// grow allocates a new empty span from the heap and initializes it for c's size class.
func (c *mcentral) grow() *mspan {
npages := uintptr(class_to_allocnpages[c.spanclass.sizeclass()])
size := uintptr(class_to_size[c.spanclass.sizeclass()])
s := mheap_.alloc(npages, c.spanclass, true)
if s == nil {
return nil
}
// Use division by multiplication and shifts to quickly compute:
// n := (npages << _PageShift) / size
//size =binary( s.divShift * uintptr(s.divMul) >> s.divShift2 )???todo
n := (npages << _PageShift) >> s.divShift * uintptr(s.divMul) >> s.divShift2
s.limit = s.base() + size*n
heapBitsForAddr(s.base()).initSpan(s)
return s
}mheap:
全局只有一个内存堆,主要可以关注mcentral和arenas相关字段;
以页为粒度(8KB,在64位上每个heapArena都会管理64MB内存)进行管理,
上面有列举出mcentral的结构体;
其中numSpanClasses=134, 其中67个为scan的mcentral,另外67个为noscan;
//
type mheap struct{
central [numSpanClasses]struct {
mcentral mcentral
pad [cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize]byte
}
}其中arenas字段在不同OS上面有不同的长度;
其长度采用的就是多级缓存思想来计算(todo???)
type mheap struct{
// arenas is the heap arena map. It points to the metadata for
// the heap for every arena frame of the entire usable virtual
// address space.
//
// Use arenaIndex to compute indexes into this array.
//
// For regions of the address space that are not backed by the
// Go heap, the arena map contains nil.
//
// Modifications are protected by mheap_.lock. Reads can be
// performed without locking; however, a given entry can
// transition from nil to non-nil at any time when the lock
// isn't held. (Entries never transitions back to nil.)
//
// In general, this is a two-level mapping consisting of an L1
// map and possibly many L2 maps. This saves space when there
// are a huge number of arena frames. However, on many
// platforms (even 64-bit), arenaL1Bits is 0, making this
// effectively a single-level map. In this case, arenas[0]
// will never be nil.
arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena
}结构体为treap,维护空闲连续page,归还内存到heap中时,连续地址会合并;
大于32KB内存申请直接从mheap中拿,剩下的则先使用当前P的mcache中对应的size class分配,如果其对应的span已经无可用的块,则向mcentral请求,如果没有则在mheap申请,如果还不够则要向操作系统申请;
初始化
回到我们的初始化,终于可以从头开始进行:
- 首先是一系列分配器,全部属于
fixAlloc,都有init方法;可以参考下一节,对每一种都详细说明 - 还会在该方法中初始化所有的
mcentral,这些mcentral会维护全局的内存管理单元,各个线程会通过mcentral获取新的内存单元。
func (h *mheap) init() {
//一系列alloc
h.spanalloc.init(unsafe.Sizeof(mspan{}), recordspan, unsafe.Pointer(h), &memstats.mspan_sys)
h.cachealloc.init(unsafe.Sizeof(mcache{}), nil, nil, &memstats.mcache_sys)
h.specialfinalizeralloc.init(unsafe.Sizeof(specialfinalizer{}), nil, nil, &memstats.other_sys)
h.specialprofilealloc.init(unsafe.Sizeof(specialprofile{}), nil, nil, &memstats.other_sys)
h.arenaHintAlloc.init(unsafe.Sizeof(arenaHint{}), nil, nil, &memstats.other_sys)
// Don't zero mspan allocations. Background sweeping can
// inspect a span concurrently with allocating it, so it's
// important that the span's sweepgen survive across freeing
// and re-allocating a span to prevent background sweeping
// from improperly cas'ing it from 0.
//
// This is safe because mspan contains no heap pointers.
h.spanalloc.zero = false
// h->mapcache needs no init
for i := range h.central {
h.central[i].mcentral.init(spanClass(i))
}
h.pages.init(&h.lock, &memstats.gc_sys)
}其中mheap自带一个alloc方法,在系统栈中获得新的mSpan:
在分配n个页面时,为了防止内存大量占用和堆的增加,会检查sweepdone字段,然后reclaim至少n个pages;
// alloc allocates a new span of npage pages from the GC'd heap.
//
// spanclass indicates the span's size class and scannability.
//
// If needzero is true, the memory for the returned span will be zeroed.
func (h *mheap) alloc(npages uintptr, spanclass spanClass, needzero bool) *mspan {
// Don't do any operations that lock the heap on the G stack.
// It might trigger stack growth, and the stack growth code needs
// to be able to allocate heap.
var s *mspan
systemstack(func() {
// To prevent excessive heap growth, before allocating n pages
// we need to sweep and reclaim at least n pages.
//会检查回收n个pages
if h.sweepdone == 0 {
h.reclaim(npages)
}
s = h.allocSpan(npages, false, spanclass, &memstats.heap_inuse)
})
if s != nil {
if needzero && s.needzero != 0 {
memclrNoHeapPointers(unsafe.Pointer(s.base()), s.npages<<_PageShift)
}
s.needzero = 0
}
return s
}接下来在mheap.allocSpan方法中,大概步骤为:
-
选择从堆上分配新的内存页和
mSpan; -
初始化
mSpan并将其加入mheap的list
- 注意有小优化,当要求的npage较小的时候
npages<pageCahcePages/4,会尝试pages.AllocToCache()拿pageCache,然后从拿到的page Cache申请内存; - 较大的时候,就会直接用
pages.Alloc()在页堆上拿内存; - 内存不足时,会调用
mheap.grow扩容并重新调用pages.Alloc(),不成功则说明OOM了,整个机器都没有内存,直接中止;
// allocSpan allocates an mspan which owns npages worth of memory.
//
// If manual == false, allocSpan allocates a heap span of class spanclass
// and updates heap accounting. If manual == true, allocSpan allocates a
// manually-managed span (spanclass is ignored), and the caller is
// responsible for any accounting related to its use of the span. Either
// way, allocSpan will atomically add the bytes in the newly allocated
// span to *sysStat.
//
// The returned span is fully initialized.
//
// h must not be locked.
//mheap不可以被锁???(初始化为什么不能被锁住???)
// allocSpan must be called on the system stack both because it acquires
// the heap lock and because it must block GC transitions.
// 但是这个allocSpan方法必须在systemstack内,因为其要用heap的锁以及要阻塞GC;
//go:systemstack
func (h *mheap) allocSpan(npages uintptr, manual bool, spanclass spanClass, sysStat *uint64) (s *mspan) {
// Function-global state.
gp := getg()
base, scav := uintptr(0), uintptr(0)
// If the allocation is small enough, try the page cache!
pp := gp.m.p.ptr()
if pp != nil && npages < pageCachePages/4 {
c := &pp.pcache
// If the cache is empty, refill it.
if c.empty() {
lock(&h.lock)
*c = h.pages.allocToCache()
unlock(&h.lock)
}
// Try to allocate from the cache.
base, scav = c.alloc(npages)
if base != 0 {
s = h.tryAllocMSpan()
if s != nil && gcBlackenEnabled == 0 && (manual || spanclass.sizeclass() != 0) {
goto HaveSpan
}
// We're either running duing GC, failed to acquire a mspan,
// or the allocation is for a large object. This means we
// have to lock the heap and do a bunch of extra work,
// so go down the HaveBaseLocked path.
//
// We must do this during GC to avoid skew with heap_scan
// since we flush mcache stats whenever we lock.
//
// TODO(mknyszek): It would be nice to not have to
// lock the heap if it's a large allocation, but
// it's fine for now. The critical section here is
// short and large object allocations are relatively
// infrequent.
}
}
// For one reason or another, we couldn't get the
// whole job done without the heap lock.
lock(&h.lock)
if base == 0 {
// Try to acquire a base address.
base, scav = h.pages.alloc(npages)
if base == 0 {
if !h.grow(npages) {
unlock(&h.lock)
return nil
}
base, scav = h.pages.alloc(npages)
if base == 0 {
throw("grew heap, but no adequate free space found")
}
}
}
if s == nil {
// We failed to get an mspan earlier, so grab
// one now that we have the heap lock.
s = h.allocMSpanLocked()
}
...
}分配到mSpan后,都要对所有字段进行初始化,一些freeindex , allocCache, gcmarkBits等
func (h *mheap) allocSpan(npages uintptr, manual bool, spanclass spanClass, sysStat *uint64) (s *mspan) {
...
HaveSpan:
// At this point, both s != nil and base != 0, and the heap
// lock is no longer held. Initialize the span.
s.init(base, npages)
if h.allocNeedsZero(base, npages) {
s.needzero = 1
}
nbytes := npages * pageSize
if manual {
s.manualFreeList = 0
s.nelems = 0
s.limit = s.base() + s.npages*pageSize
// Manually managed memory doesn't count toward heap_sys.
mSysStatDec(&memstats.heap_sys, s.npages*pageSize)
s.state.set(mSpanManual)
} else {
// We must set span properties before the span is published anywhere
// since we're not holding the heap lock.
s.spanclass = spanclass
if sizeclass := spanclass.sizeclass(); sizeclass == 0 {
s.elemsize = nbytes
s.nelems = 1
s.divShift = 0
s.divMul = 0
s.divShift2 = 0
s.baseMask = 0
} else {
s.elemsize = uintptr(class_to_size[sizeclass])
s.nelems = nbytes / s.elemsize
m := &class_to_divmagic[sizeclass]
s.divShift = m.shift
s.divMul = m.mul
s.divShift2 = m.shift2
s.baseMask = m.baseMask
}
// Initialize mark and allocation structures.
s.freeindex = 0
s.allocCache = ^uint64(0) // all 1s indicating all free.
s.gcmarkBits = newMarkBits(s.nelems)
s.allocBits = newAllocBits(s.nelems)
// It's safe to access h.sweepgen without the heap lock because it's
// only ever updated with the world stopped and we run on the
// systemstack which blocks a STW transition.
atomic.Store(&s.sweepgen, h.sweepgen)
// Now that the span is filled in, set its state. This
// is a publication barrier for the other fields in
// the span. While valid pointers into this span
// should never be visible until the span is returned,
// if the garbage collector finds an invalid pointer,
// access to the span may race with initialization of
// the span. We resolve this race by atomically
// setting the state after the span is fully
// initialized, and atomically checking the state in
// any situation where a pointer is suspect.
s.state.set(mSpanInUse)
}
...
}- fixalloc
一个不定长度的列表,用来管理不在堆上的固定的对象,这些对象都是runtime上大小固定的结构,比如mspan,mcache
-
mstatisitc
提供管理信息
扩容
mheap的grow()方法扩容,会从堆中拿回最少的npage(期望)需要的内存,并返回成功与否,并且整个过程一定要被锁住;
- 如果在当前的
arena无足够的空间,会向OS要求分配更多的arena空间(但不保证连续,所以我们需要请求整个chunks) - 接着会扩容
arena区域,并更新页分配器的metadata - heap增长,要考虑回收一部分内存,在某些情况(???哪些)会调用
scavenge回收一些空闲的内存页;
func (h *mheap) grow(npage uintptr) bool {
// We must grow the heap in whole palloc chunks.
ask := alignUp(npage, pallocChunkPages) * pageSize
totalGrowth := uintptr(0)
nBase := alignUp(h.curArena.base+ask, physPageSize)
if nBase > h.curArena.end {
// Not enough room in the current arena. Allocate more
// arena space. This may not be contiguous with the
// current arena, so we have to request the full ask.
av, asize := h.sysAlloc(ask)
if av == nil {
print("runtime: out of memory: cannot allocate ", ask, "-byte block (", memstats.heap_sys, " in use)\n")
return false
}
if uintptr(av) == h.curArena.end {
// The new space is contiguous with the old
// space, so just extend the current space.
h.curArena.end = uintptr(av) + asize
} else {
// The new space is discontiguous. Track what
// remains of the current space and switch to
// the new space. This should be rare.
if size := h.curArena.end - h.curArena.base; size != 0 {
h.pages.grow(h.curArena.base, size)
totalGrowth += size
}
// Switch to the new space.
h.curArena.base = uintptr(av)
h.curArena.end = uintptr(av) + asize
}
// The memory just allocated counts as both released
// and idle, even though it's not yet backed by spans.
//
// The allocation is always aligned to the heap arena
// size which is always > physPageSize, so its safe to
// just add directly to heap_released.
mSysStatInc(&memstats.heap_released, asize)
mSysStatInc(&memstats.heap_idle, asize)
// Recalculate nBase
nBase = alignUp(h.curArena.base+ask, physPageSize)
}
// Grow into the current arena.
v := h.curArena.base
h.curArena.base = nBase
h.pages.grow(v, nBase-v)
totalGrowth += nBase - v
// We just caused a heap growth, so scavenge down what will soon be used.
// By scavenging inline we deal with the failure to allocate out of
// memory fragments by scavenging the memory fragments that are least
// likely to be re-used.
if retained := heapRetained(); retained+uint64(totalGrowth) > h.scavengeGoal {
todo := totalGrowth
if overage := uintptr(retained + uint64(totalGrowth) - h.scavengeGoal); todo > overage {
todo = overage
}
h.pages.scavenge(todo, true)
}
return true
}其中sysAlloc是尝试申请虚拟内存,大概分为以下步骤:
- 先在预留的区域申请内存,这里会使用
linearAlloc.alloc方法;
func (h *mheap) sysAlloc(n uintptr) (v unsafe.Pointer, size uintptr) {
n = alignUp(n, heapArenaBytes)
// 1. First, try the arena pre-reservation.
v = h.arena.alloc(n, heapArenaBytes, &memstats.heap_sys)
if v != nil {
size = n
goto mapped
}
...- 然后尝试用拿回的值预留的内存中申请一块可以使用的空间,如果无可用空间,就会根据
arenaHints在目标地址上尝试扩容;
func (h *mheap) sysAlloc(n uintptr) (v unsafe.Pointer, size uintptr) {
...
// Try to grow the heap at a hint address.
for h.arenaHints != nil {
hint := h.arenaHints
p := hint.addr
if hint.down {
p -= n
}
if p+n < p {
// We can't use this, so don't ask.
v = nil
} else if arenaIndex(p+n-1) >= 1<<arenaBits {
// Outside addressable heap. Can't use.
v = nil
} else {
//
v = sysReserve(unsafe.Pointer(p), n)
}
if p == uintptr(v) {
// Success. Update the hint.
if !hint.down {
p += n
}
hint.addr = p
size = n
break
}
// Failed. Discard this hint and try the next.
//
// TODO: This would be cleaner if sysReserve could be
// told to only return the requested address. In
// particular, this is already how Windows behaves, so
// it would simplify things there.
if v != nil {
sysFree(v, n, nil)
}
h.arenaHints = hint.next
h.arenaHintAlloc.free(unsafe.Pointer(hint))
}
if size == 0 {
if raceenabled {
// The race detector assumes the heap lives in
// [0x00c000000000, 0x00e000000000), but we
// just ran out of hints in this region. Give
// a nice failure.
throw("too many address space collisions for -race mode")
}
// All of the hints failed, so we'll take any
// (sufficiently aligned) address the kernel will give
// us.
v, size = sysReserveAligned(nil, n, heapArenaBytes)
if v == nil {
return nil, 0
}
// Create new hints for extending this region.
hint := (*arenaHint)(h.arenaHintAlloc.alloc())
hint.addr, hint.down = uintptr(v), true
hint.next, mheap_.arenaHints = mheap_.arenaHints, hint
hint = (*arenaHint)(h.arenaHintAlloc.alloc())
hint.addr = uintptr(v) + size
hint.next, mheap_.arenaHints = mheap_.arenaHints, hint
}
...
//从Reserved状态到Prepared状态
sysMap(v, size, &memstats.heap_sys)
...
}- 到达mapped状态后,会初始化一个新的
heapArena来管理刚刚申请的内存空间,该结构体会被加入页堆的二维数组中
func (h *mheap) sysAlloc(n uintptr) (v unsafe.Pointer, size uintptr) {
...
mapped:
// Create arena metadata.
for ri := arenaIndex(uintptr(v)); ri <= arenaIndex(uintptr(v)+size-1); ri++ {
l2 := h.arenas[ri.l1()]
if l2 == nil {
// Allocate an L2 arena map.
l2 = (*[1 << arenaL2Bits]*heapArena)(persistentalloc(unsafe.Sizeof(*l2), sys.PtrSize, nil))
if l2 == nil {
throw("out of memory allocating heap arena map")
}
atomic.StorepNoWB(unsafe.Pointer(&h.arenas[ri.l1()]), unsafe.Pointer(l2))
}
if l2[ri.l2()] != nil {
throw("arena already initialized")
}
var r *heapArena
r = (*heapArena)(h.heapArenaAlloc.alloc(unsafe.Sizeof(*r), sys.PtrSize, &memstats.gc_sys))
if r == nil {
r = (*heapArena)(persistentalloc(unsafe.Sizeof(*r), sys.PtrSize, &memstats.gc_sys))
if r == nil {
throw("out of memory allocating heap arena metadata")
}
}
// Add the arena to the arenas list.
if len(h.allArenas) == cap(h.allArenas) {
size := 2 * uintptr(cap(h.allArenas)) * sys.PtrSize
if size == 0 {
size = physPageSize
}
newArray := (*notInHeap)(persistentalloc(size, sys.PtrSize, &memstats.gc_sys))
if newArray == nil {
throw("out of memory allocating allArenas")
}
oldSlice := h.allArenas
*(*notInHeapSlice)(unsafe.Pointer(&h.allArenas)) = notInHeapSlice{newArray, len(h.allArenas), int(size / sys.PtrSize)}
copy(h.allArenas, oldSlice)
// Do not free the old backing array because
// there may be concurrent readers. Since we
// double the array each time, this can lead
// to at most 2x waste.
}
//保存每个mapped的arena的index;
h.allArenas = h.allArenas[:len(h.allArenas)+1]
h.allArenas[len(h.allArenas)-1] = ri
// Store atomically just in case an object from the
// new heap arena becomes visible before the heap lock
// is released (which shouldn't happen, but there's
// little downside to this).
atomic.StorepNoWB(unsafe.Pointer(&l2[ri.l2()]), unsafe.Pointer(r))
}
}内存策略:
堆上的所有对象都会通过runtime.newobject方法分配内存,该方法会调用mallocgc分配指定内存大小的空间:
其中申请的大小类型不同会有不同行为:
小对象(小于32K)和大对象的不同
- 小于32KB的小对象时,会直接去 P (process)的cache的list里面拿,大于32KB的才去堆拿; 拿的过程会roundup一下大小,然后在当前P的mcachexmspan
// Allocate an object of size bytes.
// Small objects are allocated from the per-P cache's free lists.
// Large objects (> 32 kB) are allocated straight from the heap.
//typ有两种,一种noscan,一种是scan,表示分配对象是否包含指针
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
if gcphase == _GCmarktermination {
throw("mallocgc called with gcphase == _GCmarktermination")
}
if size == 0 {
return unsafe.Pointer(&zerobase)
}
......
// Set mp.mallocing to keep from being preempted by GC.
//设置状态位,为正在分配mallocing,防止被GC抢占
mp := acquirem()
if mp.mallocing != 0 {
throw("malloc deadlock")
}
if mp.gsignal == getg() {
throw("malloc during signal")
}
mp.mallocing = 1
shouldhelpgc := false
dataSize := size
c := gomcache()
var x unsafe.Pointer
noscan := typ == nil || typ.ptrdata == 0
if size <= maxSmallSize {
...
//tiny对象与小对象的分配,见下一节
} else {
//大对象
var s *mspan
shouldhelpgc = true
systemstack(func() {
s = largeAlloc(size, needzero, noscan)
})
s.freeindex = 1
s.allocCount = 1
x = unsafe.Pointer(s.base())
size = s.elemsize
}
var scanSize uintptr
if !noscan {
// If allocating a defer+arg block, now that we've picked a malloc size
// large enough to hold everything, cut the "asked for" size down to
// just the defer header, so that the GC bitmap will record the arg block
// as containing nothing at all (as if it were unused space at the end of
// a malloc block caused by size rounding).
// The defer arg areas are scanned as part of scanstack.
if typ == deferType {
dataSize = unsafe.Sizeof(_defer{})
}
heapBitsSetType(uintptr(x), size, dataSize, typ)
if dataSize > typ.size {
// Array allocation. If there are any
// pointers, GC has to scan to the last
// element.
if typ.ptrdata != 0 {
scanSize = dataSize - typ.size + typ.ptrdata
}
} else {
scanSize = typ.ptrdata
}
c.local_scan += scanSize
}
// Ensure that the stores above that initialize x to
// type-safe memory and set the heap bits occur before
// the caller can make x observable to the garbage
// collector. Otherwise, on weakly ordered machines,
// the garbage collector could follow a pointer to x,
// but see uninitialized memory or stale heap bits.
publicationBarrier()
// Allocate black during GC.
// All slots hold nil so no scanning is needed.
// This may be racing with GC so do it atomically if there can be
// a race marking the bit.
if gcphase != _GCoff {
gcmarknewobject(uintptr(x), size, scanSize)
}
if raceenabled {
racemalloc(x, size)
}
if msanenabled {
msanmalloc(x, size)
}
mp.mallocing = 0
releasem(mp)
if debug.allocfreetrace != 0 {
tracealloc(x, size, typ)
}
if rate := MemProfileRate; rate > 0 {
if rate != 1 && size < c.next_sample {
c.next_sample -= size
} else {
mp := acquirem()
profilealloc(mp, x, size)
releasem(mp)
}
}
...
return x
}各种分配器
TinyAllocator
上面的源代码中,当size<=maxSmallSize时,实际上调用了一种tinyAllocator的分配器
该分配是 会结合多个申请内存请求 成为 申请一个内存块的请求(即合并小对象存储下来); 所以当所有的子对象都不可达时,这个内存块才会被释放(同时这些对象一定不含指针,这个很好理解,有指针又要从指针处进行可达性查询) 作用是避免可能内存浪费
其中这个maxTinySize是可调整的,调整成8bytes就一定不会浪费任何内存(一个页就8B),但是这样就没什么意义(不用combine) 照这个道理,16bytes就可能会造成2× 最坏情况的内存浪费,32B就会造成4×最坏情况的内存浪费
-
其中从tinyallocator分配的对象不能被显式释放(?),所以每次我们显式释放对象的时候,自然的要保证这个对象是大于maxTinySize
-
主要的对象是一些小字符串和一些独立的变量,json的benchmark使用了这个分配器,减少了20%的堆size
其结构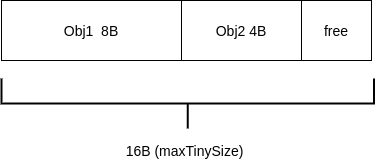
- 每个P在本地维护了专门的memory block来存储tinyObject,分配时根据tinyoffset和需要的size及对齐来判断该block是否容纳该object,如果可以就返回地址
大概流程为:
-
offset要进行roundup,
mcache的tiny字段实际指向了maxTinySize大小的块,块中如果还有合适的内存,会通过基地址和位移来获取这块内存; -
当内存块不含有合适的内存时,就会从
spanClass获得对应的mspan,然后调用runtime.nextFreeIndex方法获得空闲内存;如果空闲内存无法获得,会接着调用mcache.nextFree方法从mcentral或者mheap中获取; -
获得空闲内存块后,会用
runtime.memclrNoHeapPointers清空空闲内存中的数据,更新tiny和tinyoffset并返回新内存块
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
....
//maxSmallsize = 32786
if size<=maxSmallSize {
//申请对象不含指针(noscan)且小于16B则会调用tiny allocator
if noscan && size < maxTinySize {
// Tiny allocator.
//
//一种分配器
// Tiny allocator combines several tiny allocation requests
// into a single memory block. The resulting memory block
// is freed when all subobjects are unreachable. The subobjects
// must be noscan (don't have pointers), this ensures that
// the amount of potentially wasted memory is bounded.
//
// Size of the memory block used for combining (maxTinySize) is tunable.
// Current setting is 16 bytes, which relates to 2x worst case memory
// wastage (when all but one subobjects are unreachable).
// 8 bytes would result in no wastage at all, but provides less
// opportunities for combining.
// 32 bytes provides more opportunities for combining,
// but can lead to 4x worst case wastage.
// The best case winning is 8x regardless of block size.
//
// Objects obtained from tiny allocator must not be freed explicitly.
// So when an object will be freed explicitly, we ensure that
// its size >= maxTinySize.
//
// SetFinalizer has a special case for objects potentially coming
// from tiny allocator, it such case it allows to set finalizers
// for an inner byte of a memory block.
//
// The main targets of tiny allocator are small strings and
// standalone escaping variables. On a json benchmark
// the allocator reduces number of allocations by ~12% and
// reduces heap size by ~20%.
off := c.tinyoffset
// Align tiny pointer for required (conservative) alignment.
if size&7 == 0 {
off = round(off, 8)
} else if size&3 == 0 {
off = round(off, 4)
} else if size&1 == 0 {
off = round(off, 2)
}
//这里发现还有剩余空间
if off+size <= maxTinySize && c.tiny != 0 {
// The object fits into existing tiny block.
//该对象适合于已有的tinyblock
//移位获得剩余空间地址
x = unsafe.Pointer(c.tiny + off)
c.tinyoffset = off + size
c.local_tinyallocs++
mp.mallocing = 0
releasem(mp)
return x
}
// Allocate a new maxTinySize block.
span := c.alloc[tinySpanClass]
//从mspan的alloccache,快速获取
v := nextFreeFast(span)
if v == 0 {
//从mcentral或mheap获取;
v, _, shouldhelpgc = c.nextFree(tinySpanClass)
}
//获得后清空内存块
x = unsafe.Pointer(v)
(*[2]uint64)(x)[0] = 0
(*[2]uint64)(x)[1] = 0
// See if we need to replace the existing tiny block with the new one
// based on amount of remaining free space.
//将tiny和tinyoffset放回内存块
if size < c.tinyoffset || c.tiny == 0 {
c.tiny = uintptr(x)
c.tinyoffset = size
}
size = maxTinySize
} else {
//在32KB以内,16B以上的小对象
var sizeclass uint8
//smallSizeMax = 1024
if size <= smallSizeMax-8 {
sizeclass = size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]
} else {
sizeclass = size_to_class128[(size-smallSizeMax+largeSizeDiv-1)/largeSizeDiv]
}
size = uintptr(class_to_size[sizeclass])
spc := makeSpanClass(sizeclass, noscan)
span := c.alloc[spc]
//大同小异,先从mspan
v := nextFreeFast(span)
if v == 0 {
//再从mcentral和mheap
v, span, shouldhelpgc = c.nextFree(spc)
}
x = unsafe.Pointer(v)
if needzero && span.needzero != 0 {
memclrNoHeapPointers(unsafe.Pointer(v), size)
}
}
}else{
....
}
....
}以上nextFreeFast从mSpan取空闲空间
- 使用
mspan.allocCache字段快速计算是否有空闲对象 - 如果有,取出并更新
mspan.freeIndex和mspan.allocCache
// nextFreeFast returns the next free object if one is quickly available.
// Otherwise it returns 0.
func nextFreeFast(s *mspan) gclinkptr {
//从右边(low-order)开始数0的个数,都是0就返回64
theBit := sys.Ctz64(s.allocCache) // Is there a free object in the allocCache?
if theBit < 64 {
result := s.freeindex + uintptr(theBit)
if result < s.nelems {
freeidx := result + 1
if freeidx%64 == 0 && freeidx != s.nelems {
return 0
}
s.allocCache >>= uint(theBit + 1)
s.freeindex = freeidx
s.allocCount++
return gclinkptr(result*s.elemsize + s.base())
}
}
return 0
}nextFree()方法,从mcache,mcentral,mheap取空间:
- 要在不被抢占的上下文环境运行,因为
mcache可能被其他P抢占; - 其实还是要先从
mSpan通过nextFreeIndex检查有无可用对象 - 无的话,会调用
mcache.refill从mcentral拿缓存(详细可见前几节),然后更新freeIndex为接下来判断是否真的拿到了准确值;
// nextFree returns the next free object from the cached span if one is available.
// Otherwise it refills the cache with a span with an available object and
// returns that object along with a flag indicating that this was a heavy
// weight allocation. If it is a heavy weight allocation the caller must
// determine whether a new GC cycle needs to be started or if the GC is active
// whether this goroutine needs to assist the GC.
//
// Must run in a non-preemptible context since otherwise the owner of
// c could change.
func (c *mcache) nextFree(spc spanClass) (v gclinkptr, s *mspan, shouldhelpgc bool) {
s = c.alloc[spc]
shouldhelpgc = false
freeIndex := s.nextFreeIndex()
if freeIndex == s.nelems {
// The span is full.
if uintptr(s.allocCount) != s.nelems {
println("runtime: s.allocCount=", s.allocCount, "s.nelems=", s.nelems)
throw("s.allocCount != s.nelems && freeIndex == s.nelems")
}
c.refill(spc)
shouldhelpgc = true
s = c.alloc[spc]
freeIndex = s.nextFreeIndex()
}
if freeIndex >= s.nelems {
throw("freeIndex is not valid")
}
v = gclinkptr(freeIndex*s.elemsize + s.base())
s.allocCount++
if uintptr(s.allocCount) > s.nelems {
println("s.allocCount=", s.allocCount, "s.nelems=", s.nelems)
throw("s.allocCount > s.nelems")
}
return
}大对象分配
接上一节,大对象的分配会调用largeAlloc方法
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
...
if size <= maxSmallSize {
....//小对象分配
}else{
var s *mspan
shouldhelpgc = true
systemstack(func() {
s = largeAlloc(size, needzero, noscan)
})
s.freeindex = 1
s.allocCount = 1
x = unsafe.Pointer(s.base())
size = s.elemsize
}
...
// Ensure that the stores above that initialize x to
// type-safe memory and set the heap bits occur before
// the caller can make x observable to the garbage
// collector. Otherwise, on weakly ordered machines,
// the garbage collector could follow a pointer to x,
// but see uninitialized memory or stale heap bits.
publicationBarrier()
// Allocate black during GC.
// All slots hold nil so no scanning is needed.
// This may be racing with GC so do it atomically if there can be
// a race marking the bit.
if gcphase != _GCoff {
gcmarknewobject(uintptr(x), size, scanSize)
}
if raceenabled {
racemalloc(x, size)
}
if msanenabled {
msanmalloc(x, size)
}
mp.mallocing = 0
releasem(mp)
if debug.allocfreetrace != 0 {
tracealloc(x, size, typ)
}
if rate := MemProfileRate; rate > 0 {
if rate != 1 && size < c.next_sample {
c.next_sample -= size
} else {
mp := acquirem()
profilealloc(mp, x, size)
releasem(mp)
}
}
if assistG != nil {
// Account for internal fragmentation in the assist
// debt now that we know it.
assistG.gcAssistBytes -= int64(size - dataSize)
}
if shouldhelpgc {
if t := (gcTrigger{kind: gcTriggerHeap}); t.test() {
gcStart(t)
}
}
}其中largeAlloc函数会计算所需要的页数,计算成8KB的倍数为对象在堆上申请内存:
func largeAlloc(size uintptr, needzero bool, noscan bool) *mspan {
// print("largeAlloc size=", size, "\n")
if size+_PageSize < size {
throw("out of memory")
}
npages := size >> _PageShift
//计算页数,PageMask= 8191,一个页8KB,不够就往上取整
if size&_PageMask != 0 {
npages++
}
// Deduct credit for this span allocation and sweep if
// necessary. mHeap_Alloc will also sweep npages, so this only
// pays the debt down to npage pages.
deductSweepCredit(npages*_PageSize, npages)
//份额内存空间
s := mheap_.alloc(npages, makeSpanClass(0, noscan), needzero)
if s == nil {
throw("out of memory")
}
s.limit = s.base() + size
heapBitsForAddr(s.base()).initSpan(s)
return s
}分配defer+arg 块
最后,如果该typ类型不是指针,还要判断其是否是defer类型,进行处理,更新local_scan
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
...
var scanSize uintptr
if !noscan {
// If allocating a defer+arg block, now that we've picked a malloc size
// large enough to hold everything, cut the "asked for" size down to
// just the defer header, so that the GC bitmap will record the arg block
// as containing nothing at all (as if it were unused space at the end of
// a malloc block caused by size rounding).
// The defer arg areas are scanned as part of scanstack.
if typ == deferType {
dataSize = unsafe.Sizeof(_defer{})
}
heapBitsSetType(uintptr(x), size, dataSize, typ)
if dataSize > typ.size {
// Array allocation. If there are any
// pointers, GC has to scan to the last
// element.
if typ.ptrdata != 0 {
scanSize = dataSize - typ.size + typ.ptrdata
}
} else {
scanSize = typ.ptrdata
}
c.local_scan += scanSize
}fixAlloc
因为我们的都知道go分配对象是在go gc heap中,并且由mspan,mcache,mcentral这些结构管理,但是这些结构的对象又是在哪里管理和分配呢?
fixalloc就是做这个的:
前面讲到fixalloc都是mheap中固定的结构
- 主要目的就是一次性分配一大块内存(注意persistentalloc方法,使用是mmap,不指定地址,分配内存不再arena范围内,从进程空间获得可能百来KB), 每次请求对应的结构体大小,释放时就放在list链表中
大概的分配有以下集中
type mheap struct{
...
spanalloc fixalloc // allocator for span*
cachealloc fixalloc // allocator for mcache*
treapalloc fixalloc // allocator for treapNodes*
specialfinalizeralloc fixalloc // allocator for specialfinalizer*
specialprofilealloc fixalloc // allocator for specialprofile*
speciallock mutex // lock for special record allocators.
arenaHintAlloc fixalloc // allocator for arenaHints
...
}有前面提到的init方法,
还可以分别通过
fixalloc.allocfixalloc.free来分配以及释放内存
一些重要参数
-
go_memstats_sys_bytes: 进程从操作系统获得内存的总字节数,包含了go运行的stack,heap还有其他数据结构相关的虚拟地址空间
-
go_memstats_heap_inuse_bytes: 在span中真正被使用的字节数;其中不包括可能已经返回到操作系统,或者可以重用进行对分配、可以将作为堆栈内存重用的字节 (?)
-
go_memstats_heap_idle_bytes: 在span中空闲的字节数;
-
go_memstats_stack_sys_bytes: 栈内存字节数;主要用于goroutine栈内存的分配;
由以上参数结合代码其实可以知道大概span在内存中有几种状态:
-
idle不包含对象或者其他数据,空闲的物理内存可以释放回OS(虚拟地址不会释放!!!),或者将其转换成inuse状态或者stack span
-
inuse,至少包含一个mheap,并且可能有空闲空间分配更多堆对象
-
stack span,只会在堆或者是栈内存其中之一
栈内存
前面提到的都是属于堆上的内存,由allocator和gc负责管理;
设计
- 寄存器
栈内存一般靠编译器来分配和释放,都是随着函数的生命周期变化而变化;
而传入到函数中,栈寄存器用于存储了
基址地址和栈顶地址, Go中则主要涉及BP和SP两个栈寄存器;
对于大顶端(目前大多数使用),栈区内存就是从高地址到低地址扩展,释放内存的时候只需要更改SP的值,操作速度极快,占用极少;
- 线程栈
对于大部分OS,分配线程栈大小默认一般是2M~4MB,但是当调用栈过深,也会对栈进行扩容
- 逃逸分析
Go会动态管理内存位置,会对对象进行逃逸分析,一般遵循:
- 指向堆上的对象的指针不能在栈中;
- 指向栈对象的指针不能在栈对象回收后存活;
栈历史以及设计
过去曾经使用过分段的栈(segmented stack),扩容的时候会创建新的栈空间,然后用链表连接起来,但是会导致两个问题:
- 如果当前goroutine栈容量接近上线,任意函数调用都会触发栈扩展,那么函数调用返回后,栈又会缩容,就有热分裂(hot split)问题;
- 还会在goroutine的栈的分配中体现,如果其超过了分段栈的扩缩容阈值,都会出现从而导致更多的工作;
现在则转向了连续栈(contiguous stack),原设计文档 核心的原理就是当原栈空间不足,就会创建一个更大的空间并把原栈中所有值都移过去; 所以当栈空间不足的时候,我们要考虑:
- 内存空间分配更大的栈
- 将旧栈的内容copy到新栈;
- 销毁并回收旧栈;
最主要就在第二步,如果有指针类型呢?因为栈改变,内存肯定也会改变(所以这里可以考虑来个映射?)
不考虑多余的映射的原因就是,之前提到的逃逸分析遵循的两个原则之一:指向堆上的对象的指针不能在栈中,意思就是这里发现的指针类型一定是指向栈内的,所以不需要考虑额外映射,就将所有**相对的变量(实际就是所有的)**一起进行调整即可。
结构
栈的结构体:
// Stack describes a Go execution stack.
// The bounds of the stack are exactly [lo, hi),
// with no implicit data structures on either side.
type stack struct {
lo uintptr
hi uintptr
}看起来很简单,但是其生成过程要从编译期到运行期代码结合:
- 编译期,
cmd/internal/obj/x86.stacksplit在调用函数前插入runtime.morestack或runtime.morestack_noctxt - 运行时,goroutine会在
runtime.mlag中调用runtime.stackalloc申请新栈空间,并在编译器插入的runtime.morestack中检查栈空间是否充足;
栈初始化
runtime/stack.go中:
主要两个结构体runtime.stackpool和runtime.stacklarge,分别表示全局栈缓存和大栈缓存,区分就是栈大小是否大于32KB;
而这两个结构体都与mSpan有关(mSpanList,mcentral中有nonempty和empty),可以认为go的栈就是分配在堆上的
// Global pool of spans that have free stacks.
// Stacks are assigned an order according to size.
// order = log_2(size/FixedStack)
// There is a free list for each order.
var stackpool [_NumStackOrders]struct {
item stackpoolItem
//同mcentral很像,就是为了内存对齐而已;
_ [cpu.CacheLinePadSize - unsafe.Sizeof(stackpoolItem{})%cpu.CacheLinePadSize]byte
}
//go:notinheap
type stackpoolItem struct {
//因为是全局栈,要加锁
mu mutex
span mSpanList
}
// Global pool of large stack spans.
var stackLarge struct {
lock mutex
free [heapAddrBits - pageShift]mSpanList // free lists by log_2(s.npages)
}再看一下初始化
func stackinit() {
if _StackCacheSize&_PageMask != 0 {
throw("cache size must be a multiple of page size")
}
for i := range stackpool {
stackpool[i].item.span.init()
}
for i := range stackLarge.free {
stackLarge.free[i].init()
}
}上面的结构stackpoolItem中有个锁,但是如果大家都用这个结构,就会发生锁竞争,所以在mcache中都增加了一个stackcache
在mcache结构上
// Number of orders that get caching. Order 0 is FixedStack
// and each successive order is twice as large.
// We want to cache 2KB, 4KB, 8KB, and 16KB stacks. Larger stacks
// will be allocated directly.
// Since FixedStack is different on different systems, we
// must vary NumStackOrders to keep the same maximum cached size.
// OS | FixedStack | NumStackOrders
// -----------------+------------+---------------
// linux/darwin/bsd | 2KB | 4
// windows/32 | 4KB | 3
// windows/64 | 8KB | 2
// plan9 | 4KB | 3
_NumStackOrders = 4 - sys.PtrSize/4*sys.GoosWindows - 1*sys.GoosPlan9
type mcache struct{
...
stackcache [_NumStackOrders]stackfreelist
...
}
type stackfreelist struct {
list gclinkptr // linked list of free stacks
size uintptr // total size of stacks in list
}Linux上 ,计算出的栈常数:
_StackCacheSize = 32768,
_FixedStack = 2048, _NumStackOrders = 4
大概结构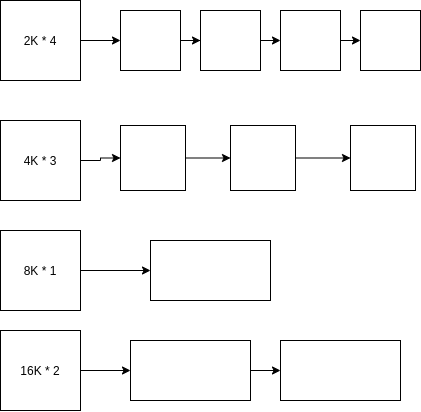
stackCache是per-P的,在另外一篇文章goroutine上讲过,主要用于分配goroutine的stack,同普通内存一样 其分为多个segment,class, linux就分为2KB,4KB,8KB,16KB等级
其中 > 16K的直接从全局stacklarge分配 否则按照先从P的stackcache分配=> 如果无法分配 => 从全局stackpool分配一批stack(stackpoolalloc),赋给该p的stackcache,再从local stackcache分配
栈的分配
分配栈空间主要是由runtime.stackalloc方法进行分配,其一定要在系统栈上运行因为其使用的是Per-P的资源且不可以切分整个栈;
-
其必须要在调度栈中运行???,所以在这个方法运行中,我们不会进行栈的扩容(否则会有死锁,可以试想栈扩容代码???)
-
小一点的的栈空间,会用全局栈
stackpool或者mcache.stackcache(固定大小空闲链表)来分配 -
栈空间较大就从全局栈
stackpool或者stackLarge分配; -
如果栈空间大的
stackLarge都拿不到,就从堆上申请;
// stackalloc allocates an n byte stack.
//
// stackalloc must run on the system stack because it uses per-P
// resources and must not split the stack.
//
//go:systemstack
func stackalloc(n uint32) stack {
// Stackalloc must be called on scheduler stack, so that we
// never try to grow the stack during the code that stackalloc runs.
// Doing so would cause a deadlock (issue 1547).
//判断是否在调度栈中
thisg := getg()
if thisg != thisg.m.g0 {
throw("stackalloc not on scheduler stack")
}
if n&(n-1) != 0 {
throw("stack size not a power of 2")
}
if stackDebug >= 1 {
print("stackalloc ", n, "\n")
}
if debug.efence != 0 || stackFromSystem != 0 {
n = uint32(alignUp(uintptr(n), physPageSize))
v := sysAlloc(uintptr(n), &memstats.stacks_sys)
if v == nil {
throw("out of memory (stackalloc)")
}
return stack{uintptr(v), uintptr(v) + uintptr(n)}
}
// Small stacks are allocated with a fixed-size free-list allocator.
// If we need a stack of a bigger size, we fall back on allocating
// a dedicated span.
//Linux amd64:
//_StackCacheSize = 32768, _FixedStack = 2048, _NumStackOrders = 4
//1. 较小的栈
var v unsafe.Pointer
if n < _FixedStack<<_NumStackOrders && n < _StackCacheSize {
order := uint8(0)
n2 := n
for n2 > _FixedStack {
order++
n2 >>= 1
}
var x gclinkptr
c := thisg.m.mcache
if stackNoCache != 0 || c == nil || thisg.m.preemptoff != "" {
//从全局pool找
// c == nil can happen in the guts of exitsyscall or
// procresize. Just get a stack from the global pool.
// Also don't touch stackcache during gc
// as it's flushed concurrently.
lock(&stackpool[order].item.mu)
x = stackpoolalloc(order)
unlock(&stackpool[order].item.mu)
} else {
//从mcache.stackCache找
x = c.stackcache[order].list
if x.ptr() == nil {
stackcacherefill(c, order)
x = c.stackcache[order].list
}
c.stackcache[order].list = x.ptr().next
c.stackcache[order].size -= uintptr(n)
}
v = unsafe.Pointer(x)
} else {
//2. 较大的栈
var s *mspan
npage := uintptr(n) >> _PageShift
log2npage := stacklog2(npage)
// Try to get a stack from the large stack cache.
//从stackLarge找
lock(&stackLarge.lock)
if !stackLarge.free[log2npage].isEmpty() {
s = stackLarge.free[log2npage].first
stackLarge.free[log2npage].remove(s)
}
unlock(&stackLarge.lock)
if s == nil {
//stackLarge找不到,只能从mheap拿
// Allocate a new stack from the heap.
s = mheap_.allocManual(npage, &memstats.stacks_inuse)
if s == nil {
throw("out of memory")
}
//这里针对某些操作系统进行的处理
osStackAlloc(s)
s.elemsize = uintptr(n)
}
v = unsafe.Pointer(s.base())
}
...栈扩容
上面说到编译期中的stackSplit会插入runtime.morestack来检查栈空间是否充足,如果不充足,
就会先保存当前栈信息,然后调用runtime.newstack来分配栈空间
-
该方法是无writebarrier(error on write barrier in this or recursive callees )的,writebarrier会引发错误,因为其可以被栈扩容的其他nowritebarrier 方法(比如???)called,
-
首先会检查是当前goroutine否可以被抢占,如果可以就触发
runtime.gogo调度器调度; 这里有个小问题,是否可以抢占其中要判断一种状态就是goroutine是否在_Grunning, 但是gc会将其状态从Gwaiting改成Gscanwaiting,所以如果遇到gc要等其完成才能继续,但是如果gc在某种情况下依赖goroutine的锁才能完成,这里就会形成死锁; 而代码中,将这个检查提前了,就可以避免;(即使状态从Grunning到Gwaiting或者反复???) -
如果被gc
runtime.scanstack方法标记了preemptShrink要收缩栈,则调用runtime.shrinkstack -
如果当前goroutine被
runtime.suspendG挂起(preemptStop),要Park当前goroutine让其他抢占,然后修改状态为_Gpreempted -
然后调用
runtime.gopreempt_m让出goroutine,实际就是调用了runtime.GoSched
// Called from runtime·morestack when more stack is needed.
// Allocate larger stack and relocate to new stack.
// Stack growth is multiplicative, for constant amortized cost.
//
// g->atomicstatus will be Grunning or Gscanrunning upon entry.
// If the scheduler is trying to stop this g, then it will set preemptStop.
//
// This must be nowritebarrierrec because it can be called as part of
// stack growth from other nowritebarrierrec functions, but the
// compiler doesn't check this.
//
//go:nowritebarrierrec
func newstack() {
thisg := getg()
...
gp := thisg.m.curg//需要扩容的栈的goroutine
...
// NOTE: stackguard0 may change underfoot, if another thread
// is about to try to preempt gp. Read it just once and use that same
// value now and below.
//这里stackguard0随时会变化,所以要用原子读;
preempt := atomic.Loaduintptr(&gp.stackguard0) == stackPreempt
// Be conservative about where we preempt.
// We are interested in preempting user Go code, not runtime code.
// If we're holding locks, mallocing, or preemption is disabled, don't
// preempt.
//在这种情况下才抢占:
//mp.locks == 0 && mp.mallocing == 0 && mp.preemptoff == "" && mp.p.ptr().status == _Prunning
// This check is very early in newstack so that even the status change
// from Grunning to Gwaiting and back doesn't happen in this case.
// That status change by itself can be viewed as a small preemption,
// because the GC might change Gwaiting to Gscanwaiting, and then
// this goroutine has to wait for the GC to finish before continuing.
// If the GC is in some way dependent on this goroutine (for example,
// it needs a lock held by the goroutine), that small preemption turns
// into a real deadlock.
if preempt {
if !canPreemptM(thisg.m) {
// Let the goroutine keep running for now.
// gp->preempt is set, so it will be preempted next time.
gp.stackguard0 = gp.stack.lo + _StackGuard
gogo(&gp.sched) // never return
}
}
if gp.stack.lo == 0 {
throw("missing stack in newstack")
}
sp := gp.sched.sp
if sys.ArchFamily == sys.AMD64 || sys.ArchFamily == sys.I386 || sys.ArchFamily == sys.WASM {
// The call to morestack cost a word.
sp -= sys.PtrSize
}
if stackDebug >= 1 || sp < gp.stack.lo {
print("runtime: newstack sp=", hex(sp), " stack=[", hex(gp.stack.lo), ", ", hex(gp.stack.hi), "]\n",
"\tmorebuf={pc:", hex(morebuf.pc), " sp:", hex(morebuf.sp), " lr:", hex(morebuf.lr), "}\n",
"\tsched={pc:", hex(gp.sched.pc), " sp:", hex(gp.sched.sp), " lr:", hex(gp.sched.lr), " ctxt:", gp.sched.ctxt, "}\n")
}
if sp < gp.stack.lo {
print("runtime: gp=", gp, ", goid=", gp.goid, ", gp->status=", hex(readgstatus(gp)), "\n ")
print("runtime: split stack overflow: ", hex(sp), " < ", hex(gp.stack.lo), "\n")
throw("runtime: split stack overflow")
}
if preempt {
if gp == thisg.m.g0 {
throw("runtime: preempt g0")
}
if thisg.m.p == 0 && thisg.m.locks == 0 {
throw("runtime: g is running but p is not")
}
if gp.preemptShrink {
// We're at a synchronous safe point now, so
// do the pending stack shrink.
gp.preemptShrink = false
shrinkstack(gp)
}
if gp.preemptStop {
preemptPark(gp) // never returns
}
// Act like goroutine called runtime.Gosched.
gopreempt_m(gp) // never return
}
...
}如果不需要抢占:
- 分配更大的空间然后移动栈,新空间是旧空间两倍,但是都会判断是否大于最大的栈(
var maxstacksize uintptr = 1 << 20) - 将goroutine的状态从
Grunning改为Gcopystack - 然后复制旧栈到新栈(期间gc是不会扫描这个goroutine,因为这个goroutine在
Gcopystack状态) - 然后将
Gcopystack状态改为Grunning,再次调用gogo
func newstack() {
...
// Allocate a bigger segment and move the stack.
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize * 2
if newsize > maxstacksize {
print("runtime: goroutine stack exceeds ", maxstacksize, "-byte limit\n")
print("runtime: sp=", hex(sp), " stack=[", hex(gp.stack.lo), ", ", hex(gp.stack.hi), "]\n")
throw("stack overflow")
}
// The goroutine must be executing in order to call newstack,
// so it must be Grunning (or Gscanrunning).
casgstatus(gp, _Grunning, _Gcopystack)
// The concurrent GC will not scan the stack while we are doing the copy since
// the gp is in a Gcopystack status.
copystack(gp, newsize)
if stackDebug >= 1 {
print("stack grow done\n")
}
casgstatus(gp, _Gcopystack, _Grunning)
gogo(&gp.sched)
}我们看到copystack函数中:
会调用stackalloc分配空间,这个之前已经讲过(从全局或者stackache或者largestack获取)
// Copies gp's stack to a new stack of a different size.
// Caller must have changed gp status to Gcopystack.
func copystack(gp *g, newsize uintptr) {
if gp.syscallsp != 0 {
throw("stack growth not allowed in system call")
}
old := gp.stack
if old.lo == 0 {
throw("nil stackbase")
}
used := old.hi - gp.sched.sp
// allocate new stack
new := stackalloc(uint32(newsize))
if stackPoisonCopy != 0 {
fillstack(new, 0xfd)
}
...
}较复杂的是,其中的指针如何复制:
-
检查stack内是否有未锁的channel,调用
runtime.adjustsudogs或runtime.syncadjustsudogs方法对runtime.sudog结构体进行调整(调整的实际就是sudog结构体,sudog represents a g in a wait list, such as for sending/receiving on a channel.); -
用
runtime.memove将旧栈(全部或剩下的数据)移到新栈; -
调整剩余的一些指针,比如
ctxt,defers,panics等等 -
其所有调整指针都会调用
runtime.adjustPointer里面利用了新栈和旧栈内存地址的差来调整指针; -
到最后调用
runtime.stackfree释放旧栈空间;
// Copies gp's stack to a new stack of a different size.
// Caller must have changed gp status to Gcopystack.
func copystack(gp *g, newsize uintptr) {
...
// Compute adjustment.
var adjinfo adjustinfo
adjinfo.old = old
adjinfo.delta = new.hi - old.hi
// Adjust sudogs, synchronizing with channel ops if necessary.
ncopy := used
if !gp.activeStackChans {
adjustsudogs(gp, &adjinfo)
} else {
// sudogs may be pointing in to the stack and gp has
// released channel locks, so other goroutines could
// be writing to gp's stack. Find the highest such
// pointer so we can handle everything there and below
// carefully. (This shouldn't be far from the bottom
// of the stack, so there's little cost in handling
// everything below it carefully.)
adjinfo.sghi = findsghi(gp, old)
// Synchronize with channel ops and copy the part of
// the stack they may interact with.
ncopy -= syncadjustsudogs(gp, used, &adjinfo)
}
// Copy the stack (or the rest of it) to the new location
memmove(unsafe.Pointer(new.hi-ncopy), unsafe.Pointer(old.hi-ncopy), ncopy)
// Adjust remaining structures that have pointers into stacks.
// We have to do most of these before we traceback the new
// stack because gentraceback uses them.
adjustctxt(gp, &adjinfo)
adjustdefers(gp, &adjinfo)
adjustpanics(gp, &adjinfo)
if adjinfo.sghi != 0 {
adjinfo.sghi += adjinfo.delta
}
// Swap out old stack for new one
//切换指向的栈
gp.stack = new
gp.stackguard0 = new.lo + _StackGuard // NOTE: might clobber a preempt request
gp.sched.sp = new.hi - used
gp.stktopsp += adjinfo.delta
// Adjust pointers in the new stack.
gentraceback(^uintptr(0), ^uintptr(0), 0, gp, 0, nil, 0x7fffffff, adjustframe, noescape(unsafe.Pointer(&adjinfo)), 0)
// free old stack
if stackPoisonCopy != 0 {
fillstack(old, 0xfc)
}
stackfree(old)
}栈缩容
前面出现过的runtime.shrinkstack
- 要先检查我们当前是不是在goroutine上(own its stack),是否安全(要有所有帧的pointers map才可以视为安全,两种情况会有不确定情况:1. syscall中 2.当前goroutine停止于 asynchronous safe point中 ),
不允许debug设置
shrinkoff缩容,不允许对gcBgMarkWorker缩容等等(还有,但是
// Maybe shrink the stack being used by gp.
//
// gp must be stopped and we must own its stack. It may be in
// _Grunning, but only if this is our own user G.
func shrinkstack(gp *g) {
if gp.stack.lo == 0 {
throw("missing stack in shrinkstack")
}
//如果不是_Gscan状态,我们无法通过这个状态获得栈,但是如果这个是我们当前使用的G,而且我们在系统栈中,就可以继续;
if s := readgstatus(gp); s&_Gscan == 0 {
// We don't own the stack via _Gscan. We could still
// own it if this is our own user G and we're on the
// system stack.
if !(gp == getg().m.curg && getg() != getg().m.curg && s == _Grunning) {
// We don't own the stack.
throw("bad status in shrinkstack")
}
}
if !isShrinkStackSafe(gp) {
throw("shrinkstack at bad time")
}
// Check for self-shrinks while in a libcall. These may have
// pointers into the stack disguised as uintptrs, but these
// code paths should all be nosplit.
//???不懂是啥东西
if gp == getg().m.curg && gp.m.libcallsp != 0 {
throw("shrinking stack in libcall")
}
if debug.gcshrinkstackoff > 0 {
return
}
f := findfunc(gp.startpc)
if f.valid() && f.funcID == funcID_gcBgMarkWorker {
// We're not allowed to shrink the gcBgMarkWorker
// stack (see gcBgMarkWorker for explanation).
return
}
...
}在一堆判断之后,确认可以缩容:
- 有个最小值,小于最小值就不缩;
- 使用容量小于原来栈的1/4就缩容,缩容为原来size的1/2
- 原来的stack包括了SP指针以下的所有内容同stackguard空间(为了给nosplit function使用,nosplit function最大可以用的),这里用
stack.hi-sched.sp+_stackLimit
func shrinkstack(gp *g) {
....
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize / 2
// Don't shrink the allocation below the minimum-sized stack
// allocation.
//linux下<2048 不缩了;
if newsize < _FixedStack {
return
}
// Compute how much of the stack is currently in use and only
// shrink the stack if gp is using less than a quarter of its
// current stack. The currently used stack includes everything
// down to the SP plus the stack guard space that ensures
// there's room for nosplit functions.
avail := gp.stack.hi - gp.stack.lo
//使用容量小于原来栈的1/4就缩容
// The maximum number of bytes that a chain of NOSPLIT
// functions can use.
//_StackLimit = _StackGuard - _StackSystem - _StackSmall
if used := gp.stack.hi - gp.sched.sp + _StackLimit; used >= avail/4 {
return
}
if stackDebug > 0 {
print("shrinking stack ", oldsize, "->", newsize, "\n")
}
copystack(gp, newsize)
}gogo继续运行goroutine
//todo ???
gogo方法是一串汇编,不会return,会直接跳出函数
// func gogo(buf *gobuf)
// restore state from Gobuf; longjmp
TEXT runtime·gogo(SB), NOSPLIT, $16-8
MOVQ buf+0(FP), BX // gobuf
MOVQ gobuf_g(BX), DX
MOVQ 0(DX), CX // make sure g != nil
get_tls(CX)
MOVQ DX, g(CX)
MOVQ gobuf_sp(BX), SP // restore SP
MOVQ gobuf_ret(BX), AX
MOVQ gobuf_ctxt(BX), DX
MOVQ gobuf_bp(BX), BP
MOVQ $0, gobuf_sp(BX) // clear to help garbage collector
MOVQ $0, gobuf_ret(BX)
MOVQ $0, gobuf_ctxt(BX)
MOVQ $0, gobuf_bp(BX)
MOVQ gobuf_pc(BX), BX
JMP BX内存对齐以及一些分配规则(补充前面的tcmalloc)
runtime/msize.go
func roundupsize(size uintptr) uintptr {
//size<32768
if size < _MaxSmallSize {
if size <= smallSizeMax-8 {
//这里面的字段是go对特定class设定的对应大小
return uintptr(class_to_size[size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]])
} else {
return uintptr(class_to_size[size_to_class128[(size-smallSizeMax+largeSizeDiv-1)/largeSizeDiv]])
}
}
//size为负数,_PageSize=1<<13
if size+_PageSize < size {
return size
}
return round(size, _PageSize)
}
//该运算在下面会提到
// round n up to a multiple of a. a must be a power of 2.
func round(n, a uintptr) uintptr {
return (n + a - 1) &^ (a - 1)
}补全的spanClass!!!
注意到class_to_size和size_to_class等等字段
[sizetoclass] 实际上在runtime/sizeclasses.go里面可以体现出go对不同大小的class设置的size: 每个span都带有一个sizeclass,即表明该span的page应该被怎么用; PS: 可以参照tcmalloc 实现思想基本一直
class0表示单独分配一个>32KB对象的span,有67个size,每个size有两种,分配用于有指针和无指针对象,所以有个67*2 = 134个class (即上面提到的numSpanClasses)
// class bytes/obj bytes/span objects tail waste max waste
// 1 8 8192 1024 0 87.50%
// 2 16 8192 512 0 43.75%
// 3 32 8192 256 0 46.88%
// 4 48 8192 170 32 31.52%
// 5 64 8192 128 0 23.44%
// 6 80 8192 102 32 19.07%
// 7 96 8192 85 32 15.95%
// 8 112 8192 73 16 13.56%
// 9 128 8192 64 0 11.72%
// 10 144 8192 56 128 11.82%
// 11 160 8192 51 32 9.73%
......
// 60 19072 57344 3 128 3.57%
// 61 20480 40960 2 0 6.87%
// 62 21760 65536 3 256 6.25%
// 63 24576 24576 1 0 11.45%
// 64 27264 81920 3 128 10.00%
// 65 28672 57344 2 0 4.91%
// 66 32768 32768 1 0 12.50%上面的代码是8B~32KB的不同class的span的大小,对象的数目,浪费的空间
如: class=3 时, 对象上限为32B,管理一个页(span=8KB),最多可以有256个对象,刚刚好
$$tailWaste = (bytes/span)mod(objects)$$
当对象为 17B的时候:
$$\frac{((32-17)*256+0)}{8192} = 0.4687$$
除了上面的66个跨度,还会存储一个ID=0的跨度,其就是用作管理大于32KB的大对象;
可以看到bytes/obj一栏,就是go预定义objects大小,最小是8B,最大是32KB(注意这里只是在32KB以内,还有大于32KB以外的),所以都可以解释到slice在扩容的时候可能会不遵守*2和1.25倍扩容的规则;
相关的main方法可以在classToSize的转换runtime/mksizeclass.go中找到
golang的位运算
有时候会经常看见会用一些全局常量:
//指针大小,一般64位就是8
const PtrSize = 4 << (^uintptr(0) >> 63) //8sys.PtrSize, sys.RegSize等等
1. ^运算
- 用作单目运算时, ^ 指的就是取反,等于一些语言的 ~ 符号(这里注意都一样取补码)
ps: 这里复习一下,
正数取反:化为二进制,得到补码(正数补码和原码一样),再对补码每位取反
负数取反:化为二进制,得到补码(所有除符号位的每位取反,+1),然后再对补码全部每位取反
x:=^3
//3=》 0011=》 1100=-4
log.Printf("%d",x)//-4
x:=^(-3)
//-3=》 1011 =》 1100 =》 1101 =》 0010=2
log.Printf("%d",x)//2也可以用比较直接的方法: ^a= -(a+1)
- 用作双目运算符时则为异或(XOR) 相同为0,相异为1
2. &^运算
将运算符号左边数据相异保留,相同置为0;
符合:
- 右侧为0,左侧数不变,
- 右侧是1,左侧清零
- 符合结合法即 a&^b=a&(^b)
经常用该符号作内存对齐 如runtime/stubs.go里面
// round n up to a multiple of a. a must be a power of 2.
func round(n, a uintptr) uintptr {
return (n + a - 1) &^ (a - 1)
}
//可以有这种说法:
//找到最大位为1的位数,然后用1左移该位数即是roundup后的结果,
//比如6 : 110,最大为为1的是在第三位,1<<3 = 1000 = 8,即十进制的8
// n=6,a=2 : 110 => (6+2-1) = 111 &^ 001 = 110runtime/malloc.go
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!