Go Scheduler
东抄西拼,Goroutine 的模型,调度等,它与普通thread有何区别?先留个坑
为什么有这个东西?
-
传统OS自带的线程一个占栈1MB,明显大的过分,所以编程语言自身得另外实现一些小的线程, 而goroutines一般就4KB左右,当然这个数值是可以调整的;
-
切换上下文的时候一般一个线程就消耗1μs,但是goroutine的切换则仅仅有0.2μs左右,大约快了80%;(里面避免了内核和用户态上的切换)
引用
《 Scalable Go Scheduler Design Doc》中有描述
Goroutines are part of making concurrency easy to use. The idea, which has been around for a while, is to multiplex independently executing functions—coroutines—onto a set of threads. When a coroutine blocks, such as by calling a blocking system call, the run-time automatically moves other coroutines on the same operating system thread to a different, runnable thread so they won’t be blocked. The programmer sees none of this, which is the point. The result, which we call goroutines, can be very cheap: unless they spend a lot of time in long-running system calls, they cost little more than the memory for the stack, which is just a few kilobytes.
大概意思就是 当系统调用阻塞,runtime环境会自动把被阻塞在当前线程内的coroutines移到另一个线程,这种在go里面就叫goroutines;
而针对goroutines的大小,也做了如下设计:
To make the stacks small, Go’s run-time uses segmented stacks. A newly minted goroutine is given a few kilobytes, which is almost always enough. When it isn’t, the run-time allocates (and frees) extension segments automatically. The overhead averages about three cheap instructions per function call. It is practical to create hundreds of thousands of goroutines in the same address space. If goroutines were just threads, system resources would run out at a much smaller number.
然后对于goroutine的栈设计,使用了分段的栈, 而且对于分段的栈增加了灵活性,当空间不足的话就会自动分配更多的空间,而且因为这个不涉及内核层面,不用保存过多信息,所以你可以在同一个地址空间里创建上千个goroutines
-
这些分段栈的基本功能
- 保护回复上下文的函数
- 运行队列processQueue
要时刻明白对于线程来讲,其阻塞指的是切换了调度队列,不再进行当前的数据控制流,如果其他流满足条件,则会移出当前队列,调度会之前的数据流。同理goroutine也只是一个结构,记录了运行的函数,运行的位置等
大致工作原理
首先go现在版本(1.13)已经是基于协作的抢占式调度;
根据历史提交,有多个部分与其相关:
-
goroutine.stackgurad0 = stackPreempt证明在抢占中 -
runtime.preemptone和runtime.preemptall会改变stackguard0字段 -
runtime.stoptheworld调用runtime.preemptall设置所有cpu上运行的goroutinestackguard0=stackPreempt -
runtime.newstack增加了抢占的代码,canPreempt()方法会让出当前goroutine -
在sysmon下,运行超过10ms的goroutine,
runtime.retake和runtime.preemptone会被执行
综上,实现其调度大概步骤:
- 编译器在其函数前插入
runtime.morestack - 在垃圾回收stw,sysmon发现goroutine运行超过10ms,就发出抢占
stackPreempt - 有函数被call时,可能会触发编译器插入的
morestack,其调用了newstack()会检查goroutine的stackguard0字段,如果是stackPreempt,就可以被抢占
以上造成的一些后果,loop下死循环等等,大部分在1.14得以解决
在1.14版本中,实现了非协作式抢占调度(增加了新的状态和字段);
-
挂起的goroutine是在gc的栈扫描(
markroot)时完成的,由runtime.suspendG和runtime.resumeG两个函数重构栈扫描这一过程;runtime.suspendG会将处于_Grunning状态的goroutine的preemptStop设为true;runtime.preemptPark(newstack也用到,当preemptStop为true时进行挂起)可以挂起当前goroutine,将其状态更新为_Gpreempted,触发重新调度,并让出当前线程控制权; -
增加
runtime.asyncPreempt和runtime.asyncPreempt2异步抢占 (汇编实现???)todo,并在runtime.preemptone增加异步逻辑; -
支持向goroutine发送信号来暂停,
runtime.sighandler函数注册SIGURG(为什么是这个信号?为啥不是见下面)处理函数SIGALRM或者其他???runtime.doSigPreempt实现runtime.preemptM,通过SIGURG向线程发送抢占;
为什么使用SIGURG,注释中写了:
// 1. It should be a signal that’s passed-through by debuggers by // default. On Linux, this is SIGALRM, SIGURG, SIGCHLD, SIGIO, // SIGVTALRM, SIGPROF, and SIGWINCH, plus some glibc-internal signals. // // 2. It shouldn’t be used internally by libc in mixed Go/C binaries // because libc may assume it’s the only thing that can handle these // signals. For example SIGCANCEL or SIGSETXID. // // 3. It should be a signal that can happen spuriously without // consequences. For example, SIGALRM is a bad choice because the // signal handler can’t tell if it was caused by the real process // alarm or not (arguably this means the signal is broken, but I // digress). SIGUSR1 and SIGUSR2 are also bad because those are often // used in meaningful ways by applications. // // 4. We need to deal with platforms without real-time signals (like // macOS), so those are out.
大概意思就是
- 要可以被debugger传输
- 不应该被libc使用
- 要有基本时序性,可以随意出现(SIGALARM就不行,不知道是不是由进程引起还是其他原因)
- 一些平台无实时信号(macOS)
调度模型
一般来说多线程调度模型有 work-sharing 和 work-stealing模型
go采用了后者,可以看看有关work-stealing的论文
架构: GPM
- G(goroutine)指的是go语言的goroutine(有些人叫它为协程,但其实跟coroutine有一点区别,因为coroutine单纯在用户态使用)
Scheduler调度过程
大概流程
调度前的检查:
- 是否分配有gc mark,如果有则要做gc mark
- 检查有无localq,有就运行
- 没有则看globalq
- 看一下net中有无poll的出来
- 从其他的p 偷一部分
禁止抢占:
func runtime_procPin() int //标记当前G在M上不会被抢占,并返回当前P的IDfunc runtime_procUnpin() //解除抢占标志这里我们有两种方法: 我们可以立即block或unblock多个M,或使其自旋; 但这里会有性能损耗和花费不必要的cpu周期,方法是使用自旋而且burn CPU cycles(???) 然而,这不应该影响在GOMAXPROCS=1的程序(command line,appengine这些)
自旋有两个等级:
- 一个已经附着了一个P的idle M 会不断自旋寻找新的Goroutines
- 一个已经附着了一个P的M 自旋等待其他可用的P 以上中,最多有GOMAXPROCS个自旋的goroutines, 等级(1)的idle M 不会阻塞 即使有等级(2)的idle M; 当新的goroutine被创建或者M进入syscall或者M从idle变成busy,它会保证至少存在一个自旋M (或者所有P是busy),
- 这就保证了不会有当前运行着的Goroutines被其他 M 运行
- 也避免了过多的 M 同时 阻塞和释放阻塞
Sysmon
用途
如果一个syscall或者是G本身的任务太长,当前G一直阻塞(因为本地队列的G是顺序执行),中止长任务就要由另外一个监控程序,即Sysmon
详情
sysmon是在runtime初始化之后,执行代码之前,由runtime启动且不与任何P绑定(所以才可以不被阻塞)直接由一个M执行的协程,类似于linux的一些系统任务内核线程
具体设置如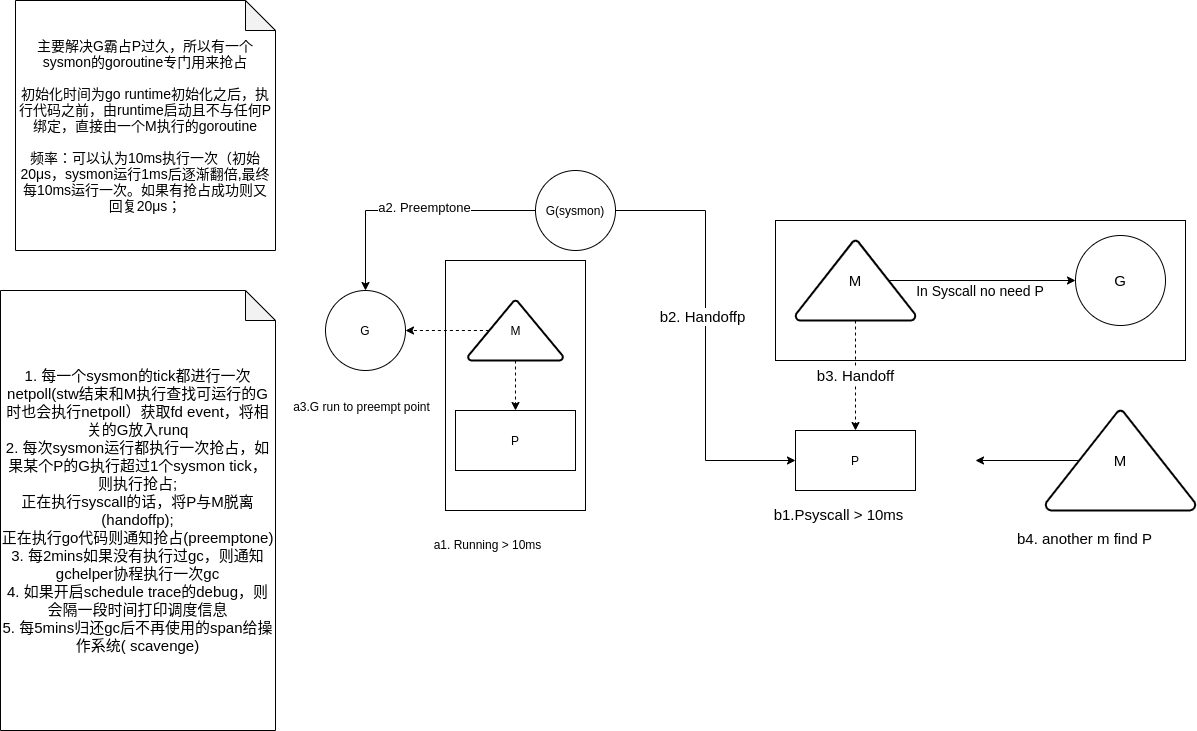
具体流程为:
- main函数启动时:
- 调用
newm创建一个存储了待执行函数(这里是sysmon的结构体runtime.m),注意其不需要P的绑定,所以goroutine会直接在这个m上面建立;
// The main goroutine.
func main() {
...
if GOARCH != "wasm" { // no threads on wasm yet, so no sysmon
systemstack(func() {
newm(sysmon, nil)
})
}
}
// Create a new m. It will start off with a call to fn, or else the scheduler.
// fn needs to be static and not a heap allocated closure.
// May run with m.p==nil, so write barriers are not allowed.
//go:nowritebarrierrec
func newm(fn func(), _p_ *p) {
mp := allocm(_p_, fn)
mp.nextp.set(_p_)
mp.sigmask = initSigmask
...
newm1(mp)
}
func newm1(mp *m) {
...
execLock.rlock() // Prevent process clone.
newosproc(mp)
execLock.runlock()
}一直调用到newosproc函数中,会clone一个新线程并在新线程中执行runtime.mstart
// May run with m.p==nil, so write barriers are not allowed.
//go:nowritebarrier
func newosproc(mp *m) {
stk := unsafe.Pointer(mp.g0.stack.hi)
// Disable signals during clone, so that the new thread starts
// with signals disabled. It will enable them in minit.
var oset sigset
sigprocmask(_SIG_SETMASK, &sigset_all, &oset)
ret := clone(cloneFlags, stk, unsafe.Pointer(mp), unsafe.Pointer(mp.g0), unsafe.Pointer(funcPC(mstart)))
sigprocmask(_SIG_SETMASK, &oset, nil)
}在新线程上,会运行传入的sysmon函数:
- 最初的休眠时间为20μs,最长的休眠时间是10ms,当sysmon在50个循环都无法唤醒goroutine时,休眠时间在每个循环都加倍
//go:nowritebarrierrec
//显然不同p绑定则不需要写屏障
func sysmon(){
//为了将绑定的M不作deadlock检查
lock(&sched.lock)
sched.nmsys++
checkdead()
unlock(&sched.lock)
for{
...
}
...
}sysmon中有一些值得探究的函数:
- 检测死锁
checkdead()
大致分为:
- 检查是否存在正在运行的线程;
- 检查是否存在正在运行的goroutine;
- 检查P上是否有计时器;
// Check for deadlock situation.
// The check is based on number of running M's, if 0 -> deadlock.
// sched.lock must be held.
func checkdead() {
...
//上面都是一些panic,buildmode问题
//mcount:根据下一个待创建的线程id和释放的线程数得到系统中存在的线程数
//即(sched.mnext - sched.nmfreed)
//sched.nmidle 处于空闲状态的M数量
//sched.nmidlelocked处于锁定状态的M数量
//sched.nmsys处于系统调用的M数量
run := mcount() - sched.nmidle - sched.nmidlelocked - sched.nmsys
if run > run0 {
//无死锁
return
}
if run < 0 {
//当前程序状态不一致
print("runtime: checkdead: nmidle=", sched.nmidle, " nmidlelocked=", sched.nmidlelocked, " mcount=", mcount(), " nmsys=", sched.nmsys, "\n")
throw("checkdead: inconsistent counts")
}
//run==0
grunning := 0
lock(&allglock)
//2.是否有运行的goroutine
for i := 0; i < len(allgs); i++ {
gp := allgs[i]
if isSystemGoroutine(gp, false) {
continue
}
s := readgstatus(gp)
switch s &^ _Gscan {
case _Gwaiting,
_Gpreempted:
grunning++
case _Grunnable,
_Grunning,
_Gsyscall:
//有死锁
unlock(&allglock)
print("runtime: checkdead: find g ", gp.goid, " in status ", s, "\n")
throw("checkdead: runnable g")
}
}
unlock(&allglock)
//循环下来,所有M都在Gidle,Gdead,Gcopystack状态下
if grunning == 0 { // possible if main goroutine calls runtime·Goexit()
//调用了goexit()
unlock(&sched.lock) // unlock so that GODEBUG=scheddetail=1 doesn't hang
throw("no goroutines (main called runtime.Goexit) - deadlock!")
}
// Maybe jump time forward for playground.
if faketime != 0 {
when, _p_ := timeSleepUntil()
if _p_ != nil {
faketime = when
for pp := &sched.pidle; *pp != 0; pp = &(*pp).ptr().link {
if (*pp).ptr() == _p_ {
*pp = _p_.link
break
}
}
mp := mget()
if mp == nil {
// There should always be a free M since
// nothing is running.
throw("checkdead: no m for timer")
}
mp.nextp.set(_p_)
notewakeup(&mp.park)
return
}
}
// There are no goroutines running, so we can look at the P's.
//3. 存在等待的goroutine切不存在running的goroutine,检查P中的计时器
for _, _p_ := range allp {
if len(_p_.timers) > 0 {
//如果有等待的计时器,则goroutine陷入Gidle是合理的,如果没有,那就永远不会唤醒,就是死锁
return
}
}
getg().m.throwing = -1 // do not dump full stacks
unlock(&sched.lock) // unlock so that GODEBUG=scheddetail=1 doesn't hang
throw("all goroutines are asleep - deadlock!")
}- 一个forloop 会不断进行以下工作:
- 计时器,获得下一个需要被触发的timer
PS: timer中管理了一个最小堆,堆顶timer就是最小时间,checkTimers方法会触发一次(但是其还不够,因为可能M都在忙,所以这里还要sysmon进行处理)
- netpoll,轮询获得需要处理的到期的fd
- 抢占(retake函数)运行时间较长的或者syscall的goroutine
- gc,符合条件时强制回收
func sysmon(){
...
for{
//一些延迟设定,每隔一定时间再去扫描
if idle == 0 { // start with 20us sleep...
delay = 20
//50个循环,加倍
} else if idle > 50 { // start doubling the sleep after 1ms...
delay *= 2
}
//超出最大,设为最大
if delay > 10*1000 { // up to 10ms
delay = 10 * 1000
}
usleep(delay)
//----------------------1.timer 计时-----------------
//next为下次tick应该发生的时间,只会由sysmon()和checkdead()调用
now := nanotime()
next, _ := timeSleepUntil()
if debug.schedtrace <= 0 && (sched.gcwaiting != 0 || atomic.Load(&sched.npidle) == uint32(gomaxprocs)) {
lock(&sched.lock)
if atomic.Load(&sched.gcwaiting) != 0 || atomic.Load(&sched.npidle) == uint32(gomaxprocs) {
//当前垃圾回收和所有处理器都处于闲置状态(npidle=gomaxprocs),且没有要触发的计时器,sysmon陷入休眠
if next > now {
atomic.Store(&sched.sysmonwait, 1)
unlock(&sched.lock)
// Make wake-up period small enough
// for the sampling to be correct.
//计算休眠的时间
sleep := forcegcperiod / 2
if next-now < sleep {
sleep = next - now
}
shouldRelax := sleep >= osRelaxMinNS
if shouldRelax {
osRelax(true)
}
//信号量同步系统监控即将进入休眠的状态
notetsleep(&sched.sysmonnote, sleep)
if shouldRelax {
osRelax(false)
}
//唤醒
now = nanotime()
next, _ = timeSleepUntil()
lock(&sched.lock)
atomic.Store(&sched.sysmonwait, 0)
//唤醒之后通知 系统监控被唤醒
noteclear(&sched.sysmonnote)
}
//唤醒后重置休眠时间
idle = 0
delay = 20
//如果在这之后,我们发现下一个计时器需要触发的时间小于当前时间,这也就说明所有的线程可能正在忙于运行 Goroutine,系统监控会启动新的线程来触发计时器,避免计时器的到期时间有较大的偏差。???
}
unlock(&sched.lock)
}
//----------------2. netpolll-------------------
// poll network if not polled for more than 10ms
//先检查网络上的调用,超过10ms没有poll过则会poll一次
lastpoll := int64(atomic.Load64(&sched.lastpoll))
if netpollinited() && lastpoll != 0 && lastpoll+10*1000*1000 < now {
//更新sched.lastpoll=now
atomic.Cas64(&sched.lastpoll, uint64(lastpoll), uint64(now))
// netpoll checks for ready network connections.
// Returns list of goroutines that become runnable.
//返回runnable的goroutine list
list := netpoll(0) // non-blocking - returns list of goroutines
if !list.empty() {
// Need to decrement number of idle locked M's
// (pretending that one more is running) before injectglist.
// Otherwise it can lead to the following situation:
// injectglist grabs all P's but before it starts M's to run the P's,
// another M returns from syscall, finishes running its G,
// observes that there is no work to do and no other running M's
// and reports deadlock.
//需要先减少lockedM的理由:
//injectglist会获取所有P 但是 在sched会启动M去运行一个P的G之前,另外一个M从syscall中返回,完成了这个G,这个时候sched启动的这个M就发现没东西去做,而且没有其他运行的M,会报deadlock todo???
incidlelocked(-1)
// Injects the list of runnable G's into the scheduler and clears glist.
//实际上会将所有goroutine状态从_Gwaiting切换到_Grunnable并加入到全局队列等待,
//如果有空闲的P,就会通过startm()来启动线程执行这些任务
injectglist(&list)
incidlelocked(1)
}
}
//todo ???为什么next<now可以说明
//有timers本来应该被运行但未运行,一种可能就是有不可抢占的P,尝试开启一个M来运行
if next < now {
// There are timers that should have already run,
// perhaps because there is an unpreemptible P.
// Try to start an M to run them.
startm(nil, false)
}
//---------------------3. 抢占retake()---------------
//重点,重新拿取在syscall的P,并且抢占长久运行的G
// retake P's blocked in syscalls
// and preempt long running G's
if retake(now) != 0 {
//抢占了,恢复20μs的间隔
idle = 0
} else {
idle++
}
//-----------------------4. gc force--------------
//还有检查是否要强制GC
// check if we need to force a GC
if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && atomic.Load(&forcegc.idle) != 0 {
lock(&forcegc.lock)
forcegc.idle = 0
var list gList
//会将用于gc的goroutine加入全局队列,让scheduler去选择p处理
list.push(forcegc.g)
injectglist(&list)
unlock(&forcegc.lock)
}
...
//trace相关
}
}主要讲一下抢占retake(),其sysmontick结构如下:
type sysmontick struct {
schedtick uint32 //处理器调度次数
schedwhen int64//处理器上次调度时间
syscalltick uint32//系统调用次数
syscallwhen int64//系统调用时间
}retake()函数:
- 当P处于
_Prunning或者_Psyscall状态时,如果上一次触发调度的时间已经过去了 10ms,我们就会通过 runtime.preemptone 抢占当前处理器; - 当P处于
_Psyscall状态时,当处理器的运行队列不为空或者不存在空闲处理器时 或者 当系统调用时间超过了 10ms,都会调用runtime.handoffp让出处理器的使用权:
func retake(now int64) uint32 {
n := 0
// Prevent allp slice changes. This lock will be completely
// uncontended unless we're already stopping the world.
//allp []*p // len(allp) == gomaxprocs; may change at safe points, otherwise immutable
//防止p的数目变化
lock(&allpLock)
// We can't use a range loop over allp because we may
// temporarily drop the allpLock. Hence, we need to re-fetch
// allp each time around the loop.
for i := 0; i < len(allp); i++ {
_p_ := allp[i]
if _p_ == nil {
// This can happen if procresize has grown
// allp but not yet created new Ps.
continue
}
pd := &_p_.sysmontick
s := _p_.status
sysretake := false
//1. 处于Prunning或者Psyscall,
if s == _Prunning || s == _Psyscall {
//p在running或者syscall太久,进行抢占!
// Preempt G if it's running for too long.
t := int64(_p_.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
//超过10ms
//抢占
preemptone(_p_)
// In case of syscall, preemptone() doesn't
// work, because there is no M wired to P.
//syscall下preemptone不会作用,因为没有M同P联系住,这里设为true只是让下面的代码少跑一轮
sysretake = true
}
}
//2. Psyscall下
if s == _Psyscall {
// Retake P from syscall if it's there for more than 1 sysmon tick (at least 20us).
t := int64(_p_.syscalltick)
if !sysretake && int64(pd.syscalltick) != t {
pd.syscalltick = uint32(t)
pd.syscallwhen = now
continue
}
// On the one hand we don't want to retake Ps if there is no other work to do,
// but on the other hand we want to retake them eventually
// because they can prevent the sysmon thread from deep sleep.
if runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now {
continue
}
// Drop allpLock so we can take sched.lock.
unlock(&allpLock)
// Need to decrement number of idle locked M's
// (pretending that one more is running) before the CAS.
// Otherwise the M from which we retake can exit the syscall,
// increment nmidle and report deadlock.
//同上面一样,防止 当前retake的M退出syscall,导致idle的M增加(nmide++),死锁发生
incidlelocked(-1)
//1.当前P运行队列不为空或者不存在空闲的P时
//2. 系统调用时间超时10ms
if atomic.Cas(&_p_.status, s, _Pidle) {
if trace.enabled {
traceGoSysBlock(_p_)
traceProcStop(_p_)
}
n++
_p_.syscalltick++
//执行syscall,handoff当前P,让出P,因为syscall的时候G是直接同M绑定的!!!
handoffp(_p_)
}
incidlelocked(1)
lock(&allpLock)
}
}
unlock(&allpLock)
return uint32(n)
}retake中的handoffp:
- 先检查本地runq有无g,如果有,直接调用
startm运行 - 检查有无gc
work(todo???是一个全局的垃圾回收结构体),如果有,调用startm开始
// Hands off P from syscall or locked M.
// Always runs without a P, so write barriers are not allowed.
//go:nowritebarrierrec
func handoffp(_p_ *p) {
// handoffp must start an M in any situation where
// findrunnable would return a G to run on _p_.
// if it has local work, start it straight away
if !runqempty(_p_) || sched.runqsize != 0 {
startm(_p_, false)
return
}
// if it has GC work, start it straight away
if gcBlackenEnabled != 0 && gcMarkWorkAvailable(_p_) {
startm(_p_, false)
return
}
// no local work, check that there are no spinning/idle M's,
// otherwise our help is not required
if atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) == 0 && atomic.Cas(&sched.nmspinning, 0, 1) { // TODO: fast atomic
startm(_p_, true)
return
}
lock(&sched.lock)
if sched.gcwaiting != 0 {
_p_.status = _Pgcstop
sched.stopwait--
if sched.stopwait == 0 {
notewakeup(&sched.stopnote)
}
unlock(&sched.lock)
return
}
if _p_.runSafePointFn != 0 && atomic.Cas(&_p_.runSafePointFn, 1, 0) {
sched.safePointFn(_p_)
sched.safePointWait--
if sched.safePointWait == 0 {
notewakeup(&sched.safePointNote)
}
}
if sched.runqsize != 0 {
unlock(&sched.lock)
startm(_p_, false)
return
}
// If this is the last running P and nobody is polling network,
// need to wakeup another M to poll network.
if sched.npidle == uint32(gomaxprocs-1) && atomic.Load64(&sched.lastpoll) != 0 {
unlock(&sched.lock)
startm(_p_, false)
return
}
if when := nobarrierWakeTime(_p_); when != 0 {
wakeNetPoller(when)
}
pidleput(_p_)
unlock(&sched.lock)
}- 最后还要判断一下是否要gc
- 将传入的
forcegc.g的list,每个g状态改为Grunnable然后放入全局sched.list; - 接着还会检查一次
sched.npidle看下有无空闲的p,调用startm(nil, false)立即开始 - 最后清空传入的
forcegc.g的list
func sysmon() {
...
for{
....
// 4. check if we need to force a GC
if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && atomic.Load(&forcegc.idle) != 0 {
lock(&forcegc.lock)
forcegc.idle = 0
var list gList
list.push(forcegc.g)
injectglist(&list)
unlock(&forcegc.lock)
}
..//trace
}
}GPM各个结构体
g (goroutine)
要注意几个fields:
- 与栈相关的, 另一篇文章提到过栈(
stackguard0用作调度器抢占式调度);
type g struct{
stack stack // offset known to runtime/cgo
//栈空间[lo,hi)
//type stack struct {
// lo uintptr
// hi uintptr
//}
stackguard0 uintptr // offset known to liblink
stackguard1 uintptr // offset known to liblink
}- 与抢占相关
在之前文章也有提到过,
g.preemptStop在抢占时会变成_Gpreemptedg.preemptShrink标记是否当前在shrink中
type g struct{
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
preemptStop bool // transition to _Gpreempted on preemption; otherwise, just deschedule
preemptShrink bool // shrink stack at synchronous safe point
}- 调度字段
type g struct{
m *m // current m; offset known to arm liblink
sched gobuf
atomicstatus uint32 //上面提到的几种状态
}其中g.sched字段就是调度时候保存的各种指针等信息,用来恢复上下文的时候使用:
依次是
-
sp,pc分别为栈指针,程序计数器 -
g当前该gobuf的goroutine -
ctxt在之前的文章讲过,复制栈的时候要把这部分指针复制,用作 -
ret系统用的return
type gobuf struct {
// The offsets of sp, pc, and g are known to (hard-coded in) libmach.
//
// ctxt is unusual with respect to GC: it may be a
// heap-allocated funcval, so GC needs to track it, but it
// needs to be set and cleared from assembly, where it's
// difficult to have write barriers. However, ctxt is really a
// saved, live register, and we only ever exchange it between
// the real register and the gobuf. Hence, we treat it as a
// root during stack scanning, which means assembly that saves
// and restores it doesn't need write barriers. It's still
// typed as a pointer so that any other writes from Go get
// write barriers.
sp uintptr
pc uintptr
g guintptr
ctxt unsafe.Pointer
ret sys.Uintreg
lr uintptr
bp uintptr // for GOEXPERIMENT=framepointer
}较全的结构
type g struct {
goid int64
// Stack parameters.
// stack describes the actual stack memory: [stack.lo, stack.hi).
// stackguard0 is the stack pointer compared in the Go stack growth prologue.
//stackguard0用作栈的指针
// It is stack.lo+StackGuard normally, but can be StackPreempt to trigger a preemption.
// stackguard1 is the stack pointer compared in the C stack growth prologue.
// It is stack.lo+StackGuard on g0 and gsignal stacks.
// It is ~0 on other goroutine stacks, to trigger a call to morestackc (and crash).
stack stack // offset known to runtime/cgo
//栈空间[lo,hi)
//type stack struct {
// lo uintptr
// hi uintptr
//}
stackguard0 uintptr // offset known to liblink
stackguard1 uintptr // offset known to liblink
...
m *m // current m; offset known to arm liblink
//调度器,上下文保存的信息所在地
sched gobuf
...
param unsafe.Pointer // passed parameter on wakeup
...
schedlink guintptr
waitsince int64 // approx time when the g become blocked
waitreason waitReason // if status==Gwaiting
...
preemptscan bool // preempted g does scan for gc
gcscandone bool // g has scanned stack; protected by _Gscan bit in status
gcscanvalid bool // false at start of gc cycle, true if G has not run since last scan; TODO: remove?
...
raceignore int8 // ignore race detection events
sysblocktraced bool // StartTrace has emitted EvGoInSyscall about this goroutine
sysexitticks int64 // cputicks when syscall has returned (for tracing)
traceseq uint64 // trace event sequencer
tracelastp puintptr // last P emitted an event for this goroutine
lockedm muintptr
//本身的寄存器状态
sig uint32
writebuf []byte
sigcode0 uintptr
sigcode1 uintptr
sigpc uintptr
gopc uintptr // pc of go statement that created this goroutine
....
startpc uintptr // pc of goroutine function
racectx uintptr
waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
.....
// Per-G GC state
// gcAssistBytes is this G's GC assist credit in terms of
// bytes allocated. If this is positive, then the G has credit
// to allocate gcAssistBytes bytes without assisting. If this
// is negative, then the G must correct this by performing
// scan work. We track this in bytes to make it fast to update
// and check for debt in the malloc hot path. The assist ratio
// determines how this corresponds to scan work debt.
gcAssistBytes int64
}M(machine)
指的就是OS原生线程,是真正调度资源的单位,M是idle或者syscall中,需要P的调度
- 其中
m.curg为当前线程上运行的用户goroutine(注意,getg()拿到的是m的当前所有类型的goroutine)
m.g0为持有调度栈的goroutine
- 还有几个处理器相关的字段:
m.p: 正在运行的处理器m.nextp:暂存的处理器m.oldp:执行系统调用之前使用的线程处理器
type m struct {
id int64
//g0是一个调用栈
g0 *g // goroutine with scheduling stack
morebuf gobuf // gobuf arg to morestack
procid uint64 // for debuggers, but offset not hard-coded
//底层的线程id
...
//这个信号处理的goroutines
gsignal *g // signal-handling g
goSigStack gsignalStack // Go-allocated signal handling stack
sigmask sigset // storage for saved signal mask
//TLS启动时候要使用
//传给FS寄存器的局部变量
tls [6]uintptr // thread-local storage (for x86 extern register)
//m启动时的函数,会传给clone
mstartfn func(){} //当前运行的goroutine,{}在语法中是错误的,这里为了使markdown解析而加上
//当前运行代码的g
curg *g // current running goroutine
caughtsig guintptr // goroutine running during fatal signal
//处理器相关,与P绑定
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
oldp puintptr // the p that was attached before executing a syscall
mallocing int32
throwing int32
//如果不等于"",没有发生抢占
preemptoff string // if != "", keep curg running on this m
locks int32
....
//m正在自旋,寻找可以attach的工作对象(P), m找不到可运行的g
spinning bool // m is out of work and is actively looking for work
blocked bool // m is blocked on a note
.....
//如果=0,则可以清空g0以及清除该m,是原子性的操作
freeWait uint32 // if == 0, safe to free g0 and delete m (atomic)
fastrand [2]uint32
needextram bool
traceback uint8
...//里面一些cgo的代码
park note
alllink *m // on allm
//调度链,是一个m的指针
schedlink muintptr
//每一个P(Per-thread)的用于存储小对象的cache,没有锁,因为都在一个P内,运行代码时绑定的p中的mcache
mcache *mcache
//goroutine的指针,uintptr可以避过写屏障, 主要用于Gobuf goroutine状态或者是那些不经过P的调度列表
//是否与某个g一直绑定
lockedg guintptr
//创建当前thread的栈
createstack [32]uintptr // stack that created this thread.
...//track用
//下一个等待锁的M
nextwaitm muintptr // next m waiting for lock
//一些锁的操作
waitunlockf func(*g, unsafe.Pointer) bool
waitlock unsafe.Pointer
waittraceev byte
waittraceskip int
startingtrace bool
syscalltick uint32
thread uintptr // thread handle
freelink *m // on sched.freem
...
//debug
dlogPerM
//表明操作系统相关
mOS
}P(Process)
指的是go语言中的调度器,M就是用P才能调度G;
可以看到P是内嵌于 M 和 G 之间的,其提供线程需要的上下文,都会负责调度线程上的waitq,使每个M可以执行多个G,并在IO时候切换G,提高效率;
p.status字段也有几种状态:
_Pidle:处理器没有运行用户代码或者调度器,被空闲队列或者改变其状态的结构持有,运行队列为空_Prunning:被线程 M 持有,并且正在执行用户代码或者调度器_Psyscall:没有执行用户代码,当前线程陷入系统调用_Pgcstop:被线程 M 持有,当前处理器由于垃圾回收被停止_Pdead:当前处理器已经不被使用
type p struct {
//每一个p都有自己的id
id int32
//状态,有_Pidle ,_Prunning,_Psyscall, _Pgcstop, _Pdead
status uint32 // one of pidle/prunning/...
link puintptr
//每次调度都会自增
schedtick uint32 // incremented on every scheduler call
syscalltick uint32 // incremented on every system call
//go程序启动时候的sysmon用
sysmontick sysmontick // last tick observed by sysmon
//指的是后面指针连接的一个m,同时该m也有一个指针连向自己 ???
m muintptr // back-link to associated m (nil if idle)
//
mcache *mcache
raceprocctx uintptr
//defer的池,defer函数,结构在此
deferpool [5][]*_defer // pool of available defer structs of different sizes (see panic.go)
deferpoolbuf [5][32]*_defer
//goroutine的id生成,能平均分到每一个idgen中
// Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen.
goidcache uint64
goidcacheend uint64
//这个就是连接的可运行的goroutines队列,可以不加锁访问(都在一个P里面,没必要加锁)
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
// runnext, if non-nil, is a runnable G that was ready'd by
// the current G and should be run next instead of what's in
// runq if there's time remaining in the running G's time
// slice. It will inherit the time left in the current time
// slice. If a set of goroutines is locked in a
// communicate-and-wait pattern, this schedules that set as a
// unit and eliminates the (potentially large) scheduling
// latency that otherwise arises from adding the ready'd
// goroutines to the end of the run queue.
//如果runnext非空,则是一个runnable状态的g,如果在当前时间片中还有剩余,则runnext指向的就是下一个应该运行的g而不使用runq里面的g,其会继承剩下的时间;
runnext guintptr
// Available G's (status == Gdead)
gFree struct {
gList
n int32
}
//sudog相关
sudogcache []*sudog
sudogbuf [128]*sudog
...//trace的一些东西
palloc persistentAlloc // per-P to avoid mutex
//用作优化内存对齐
_ uint32 // Alignment for atomic fields below
// Per-P GC state
gcAssistTime int64 // Nanoseconds in assistAlloc
gcFractionalMarkTime int64 // Nanoseconds in fractional mark worker (atomic)
gcBgMarkWorker guintptr // (atomic)
gcMarkWorkerMode gcMarkWorkerMode
// gcMarkWorkerStartTime is the nanotime() at which this mark
// worker started.
gcMarkWorkerStartTime int64
// gcw is this P's GC work buffer cache. The work buffer is
// filled by write barriers, drained by mutator assists, and
// disposed on certain GC state transitions.
gcw gcWork
// wbBuf is this P's GC write barrier buffer.
//
// TODO: Consider caching this in the running G.
wbBuf wbBuf
runSafePointFn uint32 // if 1, run sched.safePointFn at next safe point
pad cpu.CacheLinePad
}ps:其实可以注意下p.runq是一个256位(???这里为什么是256呢,有一个讲法就是一般一个cache line是128,在多核情况下,256的设置会避免拿cache的失败)的循环列表
SchedDt 调度器
主要在runtime.schedinit()上:
涉及了GPM几个部分的初始化,其中其实还有其他cpu信息等初始化:
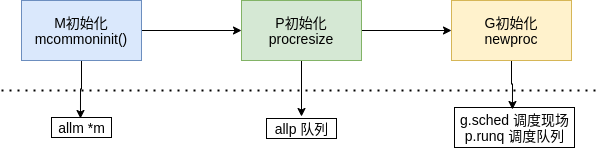
初始化m
通过mcommoninit()方法初始化allm
func mcommoninit(mp *m) {
_g_ := getg()
// g0 stack won't make sense for user (and is not necessary unwindable).
if _g_ != _g_.m.g0 {
callers(1, mp.createstack[:])
}
lock(&sched.lock)
if sched.mnext+1 < sched.mnext {
throw("runtime: thread ID overflow")
}
mp.id = sched.mnext
sched.mnext++
checkmcount()
mp.fastrand[0] = uint32(int64Hash(uint64(mp.id), fastrandseed))
mp.fastrand[1] = uint32(int64Hash(uint64(cputicks()), ^fastrandseed))
if mp.fastrand[0]|mp.fastrand[1] == 0 {
mp.fastrand[1] = 1
}
mpreinit(mp)
if mp.gsignal != nil {
mp.gsignal.stackguard1 = mp.gsignal.stack.lo + _StackGuard
}
// Add to allm so garbage collector doesn't free g->m
// when it is just in a register or thread-local storage.
mp.alllink = allm
// NumCgoCall() iterates over allm w/o schedlock,
// so we need to publish it safely.
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
unlock(&sched.lock)
// Allocate memory to hold a cgo traceback if the cgo call crashes.
if iscgo || GOOS == "solaris" || GOOS == "illumos" || GOOS == "windows" {
mp.cgoCallers = new(cgoCallers)
}
}初始化p(procresize)
- 设置了maxcount,可以有10000个线程,但是同时运行的线程仍然受
GOMAXPROCS设置影响 - 获取最大运行procs后会调用
procresize来更新程序中处理器数量,调度器进入锁定状态,不会执行任何goroutine
// The bootstrap sequence is:
//
// call osinit
// call schedinit
// make & queue new G
// call runtime·mstart
//
// The new G calls runtime·main.
func schedinit() {
// raceinit must be the first call to race detector.
// In particular, it must be done before mallocinit below calls racemapshadow.
_g_ := getg()
...
sched.maxmcount = 10000
....
sched.lastpoll = uint64(nanotime())
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
}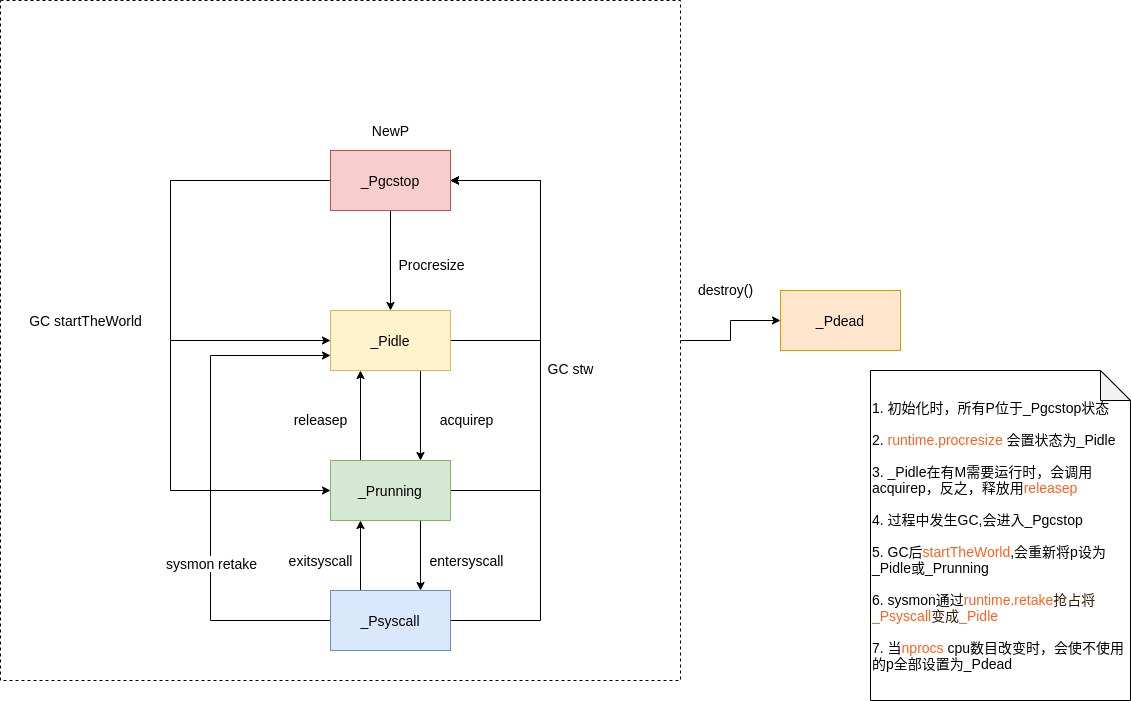
P在GOMAXPROCS中,所有的P被组织成一个数组,当GOMAXPROCS改变时会触发 stop the world来重新调整P 数组的长度
一些变量会从sched中分离出到P中;
procresize大概流程:
- 记录一下调度时间
sched.procresizetime; - 如果全局
allpslice 小于期望值,会对其扩容; - new一个新的处理器结构体,并调用
runtime.p.init方法初始化allp里面的p(会将其状态设为_Pgcstop,这个函数可用于创建新的p或复用之前销毁的p); - 如果当前p还可以使用,将p设为
_Prunning; - 否则将当前
m和allp[0]绑定 destroy方法释放不使用的旧P;- Trim一下
allp使其跟传入的nproc长度相等 allpslice 中除去当前p之外,将其中的任务通过pidleput()方法将无任务的p放入全局sched.pidle队列- 除去当前p之外,将有任务的p放入p的
link结构,连成一个链表
因为运行初始化p的时候,是刚刚初始化M结束,因此第 6 步中的绑定 M 会将当前的 P 绑定到初始 M 上;
而后由于程序刚刚开始,P 队列是空的,所以他们都会被链接到可运行的 P link上处于 _Pidle 状态
// Change number of processors. The world is stopped, sched is locked.
// gcworkbufs are not being modified by either the GC or
// the write barrier code.
// Returns list of Ps with local work, they need to be scheduled by the caller.
func procresize(nprocs int32) *p {
old := gomaxprocs
if old < 0 || nprocs <= 0 {
throw("procresize: invalid arg")
}
if trace.enabled {
traceGomaxprocs(nprocs)
}
// update statistics
now := nanotime()
if sched.procresizetime != 0 {
sched.totaltime += int64(old) * (now - sched.procresizetime)
}
sched.procresizetime = now
// Grow allp if necessary.
//1. 扩容allp
if nprocs > int32(len(allp)) {
// Synchronize with retake, which could be running
// concurrently since it doesn't run on a P.
lock(&allpLock)
if nprocs <= int32(cap(allp)) {
allp = allp[:nprocs]
} else {
nallp := make([]*p, nprocs)
// Copy everything up to allp's cap so we
// never lose old allocated Ps.
copy(nallp, allp[:cap(allp)])
allp = nallp
}
unlock(&allpLock)
}
// initialize new P's
//2. 初始化新P
for i := old; i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)
}
pp.init(i)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}
_g_ := getg()
//当前p存在,且不是在缩小CPU后(id在nprocs范围内)
if _g_.m.p != 0 && _g_.m.p.ptr().id < nprocs {
// continue to use the current P
_g_.m.p.ptr().status = _Prunning
_g_.m.p.ptr().mcache.prepareForSweep()
} else {
//3. 将当前m和`allp[0]`绑定,并设置p为_Pidle状态
// release the current P and acquire allp[0].
//
// We must do this before destroying our current P
// because p.destroy itself has write barriers, so we
// need to do that from a valid P.
if _g_.m.p != 0 {
if trace.enabled {
// Pretend that we were descheduled
// and then scheduled again to keep
// the trace sane.
traceGoSched()
traceProcStop(_g_.m.p.ptr())
}
_g_.m.p.ptr().m = 0
}
_g_.m.p = 0
_g_.m.mcache = nil
p := allp[0]
p.m = 0
p.status = _Pidle
acquirep(p)
if trace.enabled {
traceGoStart()
}
}
//4.
// release resources from unused P's
for i := nprocs; i < old; i++ {
p := allp[i]
p.destroy()
// can't free P itself because it can be referenced by an M in syscall
}
// Trim allp.
if int32(len(allp)) != nprocs {
lock(&allpLock)
allp = allp[:nprocs]
unlock(&allpLock)
}
var runnablePs *p
for i := nprocs - 1; i >= 0; i-- {
p := allp[i]
if _g_.m.p.ptr() == p {
continue
}
p.status = _Pidle
//无任务的p,放入全局队列sched.pidle
if runqempty(p) {
pidleput(p)
} else {
//有任务的p,放入链表
p.m.set(mget())
p.link.set(runnablePs)
runnablePs = p
}
}
stealOrder.reset(uint32(nprocs))
var int32p *int32 = &gomaxprocs // make compiler check that gomaxprocs is an int32
atomic.Store((*uint32)(unsafe.Pointer(int32p)), uint32(nprocs))
return runnablePs
}type schedt struct{
lock mutex//锁用于调用globalq的时候使用
// When increasing nmidle, nmidlelocked, nmsys, or nmfreed, be
// sure to call checkdead().
//空闲的m
midle muintptr // idle m's waiting for work
nmidle int32 // number of idle m's waiting for work
nmidlelocked int32 // number of locked m's waiting for work
mnext int64 // number of m's that have been created and next M ID
maxmcount int32 // maximum number of m's allowed (or die)
nmsys int32 // number of system m's not counted for deadlock
nmfreed int64 // cumulative number of freed m's
ngsys uint32 // number of system goroutines; updated atomically
//空闲的p
pidle puintptr // idle p's
npidle uint32
//在spinning状态的m的数量
nmspinning uint32 // See "Worker thread parking/unparking" comment in proc.go.
// Global runnable queue.
//可运行 的globalq
runq gQueue
runqsize int32
// disable controls selective disabling of the scheduler.
//
// Use schedEnableUser to control this.
//
// disable is protected by sched.lock.
disable struct {
// user disables scheduling of user goroutines.
user bool
runnable gQueue // pending runnable Gs
n int32 // length of runnable
}
// Global cache of dead G's.
//全局空余剩下的g
gFree struct {
lock mutex
stack gList // Gs with stacks
noStack gList // Gs without stacks
n int32
}
}相关结构可以在runtime/runtime2.go 中找到
初始化生成新的goroutine
g的状态转换图:
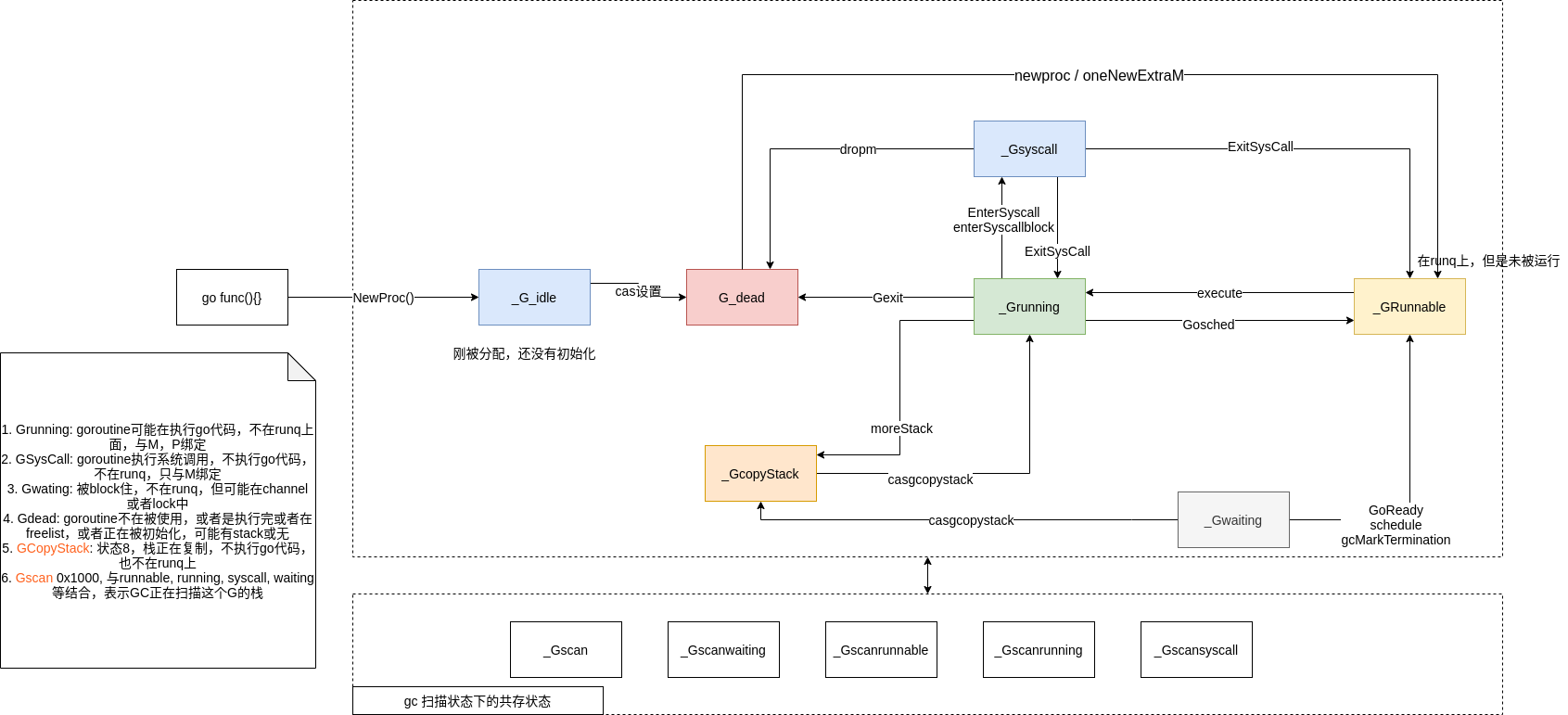
状态的详细描述:
_Gidle:刚刚被分配还没有初始化_Grunnable: 没有执行代码,没有栈的所有权,存储在runq(local or global???)中;_Grunning:可以执行代码,拥有栈的所有权,绑定了M,P;_Gsyscall: 正在执行系统调用,拥有栈的所有权,没有执行用户代码,被赋予了内核线程 M 但是不在运行队列上;_Gwaiting:由于运行时而被阻塞,没有执行用户代码并且不在runq上,但是可能存在于Channel的等待队列上或者lock内等等;_Gdead: 没有被使用,没有执行代码,可能有分配的栈???,或者在gFree(g的一个字段,全部状态都是Gdead);_Gcopystack:栈正在被拷贝,没有执行代码,不在运行队列上;_Gpreempted:由于抢占而被阻塞,没有执行用户代码并且不在运行队列上,等待唤醒;_Gscan: GC 正在扫描栈空间,没有执行代码,可以与其他状态同时存(其值为0x1000,其他有些状态比如_GscanRunning=2,直接加上去)
当有新的Goroutine被创建或者是现存的goroutine更新为runnable状态,它会被push到当前P的runnable goroutine list里面, 当P完成了执行goroutine,它会
- 首先从自己的runnable g list里面pop一个goroutine,如果list是空的,它会随机选取其他P,并且偷取其list的一半runnable goroutine
当M 创建了新的goroutine,它要保证有其他M执行这个goroutine 同样的,如果M进入了syscall阶段,它也要保证有其他M可以执行这个goroutine
语言层面上,当然是编译器先检查有无go关键字,在编译期:
cmd/compile/internal/gc.state.stmt和cmd/compile/internal/gc.state.call会将其转换成runtime.newproc函数
??? 不懂,ssa要学一下才行了
func (s *state) call(n *Node, k callKind) *ssa.Value {
if k == callDeferStack {
...
} else {
switch {
case k == callGo:
call = s.newValue1A(ssa.OpStaticCall, types.TypeMem, newproc, s.mem())
default:
}
}
...
}runtime.newproc函数,使用了g0系统栈创建goroutine,还有go后面接着的function,传入参数有:fn函数入口地址,argp为参数起始地址,siz参数长度,gp(g0),调用方pc(goroutine)(因为其假定了函数的传入参数一定跟在fn的地址后面,如果split了栈,则无法寻找到对应的传入参数,所以加上nosplit)
// Create a new g running fn with siz bytes of arguments.
// Put it on the queue of g's waiting to run.
// The compiler turns a go statement into a call to this.
// Cannot split the stack because it assumes that the arguments
// are available sequentially after &fn; they would not be
// copied if a stack split occurred.
//go:nosplit
func newproc(siz int32, fn *funcval) {
// 从 fn 的地址增加一个指针的长度,从而获取第一参数地址
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
gp := getg()
pc := getcallerpc()// 获取调用方 PC/IP 寄存器值
//用 g0 系统栈创建goroutine
systemstack(func() {
// fn 函数入口地址, argp 为参数起始地址, siz 参数长度, gp(g0),调用方 pc(goroutine)
newproc1(fn, argp, siz, gp, pc)
})
}
type funcval struct {
fn uintptr
//变长的变量,fn数据的头部指针
// variable-size, fn-specific data here
}
//caller的pc值
func getcallerpc() uintptr看一个例子:
package main
func sayhi(s string){
println(s)
}
func main() {
go sayhi("hi")
}汇编解析:
0x0000 00000 (/home/main.go:7) TEXT "".main(SB), ABIInternal, $40-0
0x0000 00000 (/home/main.go:7) MOVQ (TLS), CX
0x0009 00009 (/home/main.go:7) CMPQ SP, 16(CX)
0x000d 00013 (/home/main.go:7) PCDATA $0, $-2
0x000d 00013 (/home/main.go:7) JLS 84
0x000f 00015 (/home/main.go:7) PCDATA $0, $-1
0x000f 00015 (/home/main.go:7) SUBQ $40, SP
0x0013 00019 (/home/main.go:7) MOVQ BP, 32(SP)
0x0018 00024 (/home/main.go:7) LEAQ 32(SP), BP
0x001d 00029 (/home/main.go:7) PCDATA $0, $-2
0x001d 00029 (/home/main.go:7) PCDATA $1, $-2
0x001d 00029 (/home/main.go:7) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB) //gc用,局部函数调用参数,需要回收
0x001d 00029 (/home/main.go:7) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x001d 00029 (/home/main.go:7) FUNCDATA $2, gclocals·9fb7f0986f647f17cb53dda1484e0f7a(SB)
0x001d 00029 (/home/main.go:8) PCDATA $0, $0
0x001d 00029 (/home/main.go:8) PCDATA $1, $0
0x001d 00029 (/home/main.go:8) MOVL $16, (SP)
0x0024 00036 (/home/main.go:8) PCDATA $0, $1
0x0024 00036 (/home/main.go:8) LEAQ "".sayhi·f(SB), AX
0x002b 00043 (/home/main.go:8) PCDATA $0, $0
0x002b 00043 (/home/main.go:8) MOVQ AX, 8(SP)
0x0030 00048 (/home/main.go:8) PCDATA $0, $1
0x0030 00048 (/home/main.go:8) LEAQ go.string."hi"(SB), AX // 将 "hi" 的地址给 AX
0x0037 00055 (/home/main.go:8) PCDATA $0, $0
0x0037 00055 (/home/main.go:8) MOVQ AX, 16(SP) // 将 AX 的值放到 16(SP)
0x003c 00060 (/home/main.go:8) MOVQ $2, 24(SP)
0x0045 00069 (/home/main.go:8) CALL runtime.newproc(SB)
0x004a 00074 (/home/main.go:9) MOVQ 32(SP), BP
0x004f 00079 (/home/main.go:9) ADDQ $40, SP
0x0053 00083 (/home/main.go:9) RET
0x0054 00084 (/home/main.go:9) NOP
0x0054 00084 (/home/main.go:7) PCDATA $1, $-1
0x0054 00084 (/home/main.go:7) PCDATA $0, $-2
0x0054 00084 (/home/main.go:7) CALL runtime.morestack_noctxt(SB)
0x0059 00089 (/home/main.go:7) PCDATA $0, $-1
0x0059 00089 (/home/main.go:7) JMP 0
LEAQ go.string.*+1874(SB), AX // 将 "hello world" 的地址给 AX
MOVQ AX, 0x10(SP) // 将 AX 的值放到 0x10
MOVL $0x10, 0(SP) // 将最后一个参数的位置存到栈顶 0x00
LEAQ go.func.*+67(SB), AX // 将 go 语句调用的函数入口地址给 AX
MOVQ AX, 0x8(SP) // 将 AX 存入 0x08
CALL runtime.newproc(SB) // 调用 newproc//???todo
栈布局
| | 高地址
| |
+-----------------+
| &"hi" |
0x16 +-----------------+ <--- fn + sys.PtrSize
| sayhi |
0x08 +-----------------+ <--- fn
| siz |
0x00 +-----------------+ SP
| newproc PC |
+-----------------+ callerpc: 要运行的 Goroutine 的 PC
| |
| | 低地址注意到会在系统栈下调用newproc1,传入的是go关键字后函数的地址,这个函数caller的pc值、goroutine,传入参数地址大小等等信息
- 首先就是创建
newg,会调用gfget从gfree链表或者全局sched.gFree(已经执行过的g)上拿到空闲的goroutine或者创建一个新的goroutine,都没有就创建一个goroutine
// Create a new g running fn with narg bytes of arguments starting
// at argp. callerpc is the address of the go statement that created
// this. The new g is put on the queue of g's waiting to run.
func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) {
_g_ := getg()
if fn == nil {
_g_.m.throwing = -1 // do not dump full stacks
throw("go of nil func value")
}
acquirem() // disable preemption because it can be holding p in a local var
siz := narg
siz = (siz + 7) &^ 7
// We could allocate a larger initial stack if necessary.
// Not worth it: this is almost always an error.
// 4*sizeof(uintreg): extra space added below
// sizeof(uintreg): caller's LR (arm) or return address (x86, in gostartcall).
if siz >= _StackMin-4*sys.RegSize-sys.RegSize {
throw("newproc: function arguments too large for new goroutine")
}
_p_ := _g_.m.p.ptr()
newg := gfget(_p_)
if newg == nil {
newg = malg(_StackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}
...
}注意到获得newg的方法中,有gfget和malg两种
-
gfget:如果是当前p的gfreelist为空,就从全局调度器sched.gFree转移到当前p上,上限为32; -
如果充足的话就会从
gfree列表头部返回一个新的goroutine;
// Get from gfree list.
// If local list is empty, grab a batch from global list.
func gfget(_p_ *p) *g {
retry:
if _p_.gFree.empty() && (!sched.gFree.stack.empty() || !sched.gFree.noStack.empty()) {
lock(&sched.gFree.lock)
// Move a batch of free Gs to the P.
for _p_.gFree.n < 32 {
// Prefer Gs with stacks.
gp := sched.gFree.stack.pop()
if gp == nil {
gp = sched.gFree.noStack.pop()
if gp == nil {
break
}
}
sched.gFree.n--
_p_.gFree.push(gp)
_p_.gFree.n++
}
unlock(&sched.gFree.lock)
goto retry
}因为这里我们讨论的是初始化,所以上述两种情况都不会发生,会直接使用下面:
malg来初始化一个新的goroutine:
call newg方法,然后分配2KB栈空间,并设为_Gidle状态(值为0)
创建完成后,其返回的值,会放入到全局allg slice上面,从_Gidle设为Gdead状态,所以gc也不会扫描这个未初始化的栈
// Allocate a new g, with a stack big enough for stacksize bytes.
func malg(stacksize int32) *g {
newg := new(g)
if stacksize >= 0 {
//stacksize = 2KB
stacksize = round2(_StackSystem + stacksize)
systemstack(func() {
newg.stack = stackalloc(uint32(stacksize))
})
newg.stackguard0 = newg.stack.lo + _StackGuard
newg.stackguard1 = ^uintptr(0)
// Clear the bottom word of the stack. We record g
// there on gsignal stack during VDSO on ARM and ARM64.
*(*uintptr)(unsafe.Pointer(newg.stack.lo)) = 0
}
return newg
}- 接下来就用
memovecopy fn的所有参数到栈中,argp和narg分别为参数内存地址和大小,根据要执行函数的入口地址和参数,初始化执行栈的SP和参数的入栈位置,并将需要的参数拷贝一份存入执行栈中;
func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) {
....
//内存对齐
totalSize := 4*sys.RegSize + uintptr(siz) + sys.MinFrameSize // extra space in case of reads slightly beyond frame
totalSize += -totalSize & (sys.SpAlign - 1) // align to spAlign
sp := newg.stack.hi - totalSize
//栈的地址
spArg := sp
if usesLR {
// caller's LR
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
spArg += sys.MinFrameSize
}
//处理传入的参数,有参数时
if narg > 0 {
//从argp的位置开始,复制narg个bytes到spArg
memmove(unsafe.Pointer(spArg), argp, uintptr(narg))
// This is a stack-to-stack copy. If write barriers
// are enabled and the source stack is grey (the
// destination is always black), then perform a
// barrier copy. We do this *after* the memmove
// because the destination stack may have garbage on
// it.
//栈到栈的copy,如果用了写屏障,且源栈为灰色(目标始终为黑色),则执行barrier copy,因为目标栈上可能有垃圾,
if writeBarrier.needed && !_g_.m.curg.gcscandone {
f := findfunc(fn.fn)
stkmap := (*stackmap)(funcdata(f, _FUNCDATA_ArgsPointerMaps))
if stkmap.nbit > 0 {
// We're in the prologue, so it's always stack map index 0.
bv := stackmapdata(stkmap, 0)
bulkBarrierBitmap(spArg, spArg, uintptr(bv.n)*sys.PtrSize, 0, bv.bytedata)
}
}
}
...- 然后复制之后,根据SP以及相关参数清理创建并初始化g的运行现场,然后将调用方、要执行的函数的入口 PC 进行保存,并将其状态改为
Grunnable;
其中gostartcallfn方法在(后面)[#调度循环]会详细聊到
func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) {
...
//// memclrNoHeapPointers clears n bytes starting at ptr.
//清除所有sched
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
//注意这里, 将pc改为,runtime.goexit 函数和
//将g改为新的goroutine
newg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
if _g_.m.curg != nil {
newg.labels = _g_.m.curg.labels
}
if isSystemGoroutine(newg, false) {
atomic.Xadd(&sched.ngsys, +1)
}
//更改状态
casgstatus(newg, _Gdead, _Grunnable)
if _p_.goidcache == _p_.goidcacheend {
// Sched.goidgen is the last allocated id,
// this batch must be [sched.goidgen+1, sched.goidgen+GoidCacheBatch].
// At startup sched.goidgen=0, so main goroutine receives goid=1.
_p_.goidcache = atomic.Xadd64(&sched.goidgen, _GoidCacheBatch)
_p_.goidcache -= _GoidCacheBatch - 1
_p_.goidcacheend = _p_.goidcache + _GoidCacheBatch
}
newg.goid = int64(_p_.goidcache)
_p_.goidcache++
...- 给 Goroutine 分配 id,并将其放入 P 本地队列的队头或全局队列(初始化阶段队列肯定不是满的,因此不可能放入全局队列),最后将初始化好的goroutine放入runq
//接上面
...
//放入runq,传入是true,放入runnext,如果是false就会放入runq的尾部
runqput(_p_, newg, true)
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 && mainStarted {
wakep()
}
releasem(_g_.m)注意这个runqput方法中
- 首先会将其放入local runnable q,并将其放入
_p_.runnext - 如果传入next为
false且本地runq未满,就会放入本地runq尾部 - 如果传入next为
true,并将其放入_p_.runnext - 如果本地runq满了,runnext会将其放入全局
sched.runq(这里创建goroutine传入的是true) - 这个只会被其拥有者P运行;
// runqput tries to put g on the local runnable queue.
// If next is false, runqput adds g to the tail of the runnable queue.
// If next is true, runqput puts g in the _p_.runnext slot.
// If the run queue is full, runnext puts g on the global queue.
// Executed only by the owner P.
func runqput(_p_ *p, gp *g, next bool) {
if randomizeScheduler && next && fastrand()%2 == 0 {
next = false
}
if next {
retryNext:
oldnext := _p_.runnext
if !_p_.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {
goto retryNext
}
if oldnext == 0 {
return
}
// Kick the old runnext out to the regular run queue.
gp = oldnext.ptr()
}
retry:
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with consumers
t := _p_.runqtail
if t-h < uint32(len(_p_.runq)) {
_p_.runq[t%uint32(len(_p_.runq))].set(gp)
atomic.StoreRel(&_p_.runqtail, t+1) // store-release, makes the item available for consumption
return
}
if runqputslow(_p_, gp, h, t) {
return
}
// the queue is not full, now the put above must succeed
goto retry
}- 检查空闲的 P,将其唤醒,准备执行 G,但我们目前处于初始化阶段,主goroutine尚未开始执行,因此这里不会唤醒 P;
提多一句,整个newproc在nosplit环境下,所以执行过程中是不会发生扩容和抢占;
调度循环
上面提到gostartcallfn方法,其还会对sched.pc和sched.sp进行一些处理:
其注释说的就是还有一些对g.sched还有一些
-
上面讲到pc实际上保存的就是程序接下来的运行地址,
buf.pc = uintptr(fn)就是从fn开始运行 -
但是这个
sp老实说我不看这文章我tm让我找都找不到原因;
// adjust Gobuf as if it executed a call to fn
// and then did an immediate gosave.
func gostartcallfn(gobuf *gobuf, fv *funcval) {
var fn unsafe.Pointer
if fv != nil {
fn = unsafe.Pointer(fv.fn)
} else {
fn = unsafe.Pointer(funcPC(nilfunc))
}
gostartcall(gobuf, fn, unsafe.Pointer(fv))
}
// adjust Gobuf as if it executed a call to fn with context ctxt
// and then did an immediate gosave.
func gostartcall(buf *gobuf, fn, ctxt unsafe.Pointer) {
sp := buf.sp
//为什么???
if sys.RegSize > sys.PtrSize {
sp -= sys.PtrSize
*(*uintptr)(unsafe.Pointer(sp)) = 0
}
sp -= sys.PtrSize
*(*uintptr)(unsafe.Pointer(sp)) = buf.pc
buf.sp = sp
buf.pc = uintptr(fn)
buf.ctxt = ctxt
}mstart开始
调度从runtime.mstart开始,无栈要求,所以no split;其因为无P,所以暂时不需要写屏障;
// mstart is the entry-point for new Ms.
//
// This must not split the stack because we may not even have stack
// bounds set up yet.
//
// May run during STW (because it doesn't have a P yet), so write
// barriers are not allowed.
//
//go:nosplit
//go:nowritebarrierrec
func mstart() {
_g_ := getg()
osStack := _g_.stack.lo == 0
if osStack {
// Initialize stack bounds from system stack.
// Cgo may have left stack size in stack.hi.
// minit may update the stack bounds.
size := _g_.stack.hi
if size == 0 {
size = 8192 * sys.StackGuardMultiplier
}
_g_.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))
_g_.stack.lo = _g_.stack.hi - size + 1024
}
// Initialize stack guard so that we can start calling regular
// Go code.
_g_.stackguard0 = _g_.stack.lo + _StackGuard
// This is the g0, so we can also call go:systemstack
// functions, which check stackguard1.
_g_.stackguard1 = _g_.stackguard0
mstart1()
// Exit this thread.
switch GOOS {
case "windows", "solaris", "illumos", "plan9", "darwin", "aix":
// Windows, Solaris, illumos, Darwin, AIX and Plan 9 always system-allocate
// the stack, but put it in _g_.stack before mstart,
// so the logic above hasn't set osStack yet.
osStack = true
}
mexit(osStack)
}
func mstart1() {
_g_ := getg()
if _g_ != _g_.m.g0 {
throw("bad runtime·mstart")
}
// Record the caller for use as the top of stack in mcall and
// for terminating the thread.
// We're never coming back to mstart1 after we call schedule,
// so other calls can reuse the current frame.
save(getcallerpc(), getcallersp())
asminit()
minit()
// Install signal handlers; after minit so that minit can
// prepare the thread to be able to handle the signals.
if _g_.m == &m0 {
mstartm0()
}
if fn := _g_.m.mstartfn; fn != nil {
fn()
}
if _g_.m != &m0 {
acquirep(_g_.m.nextp.ptr())
_g_.m.nextp = 0
}
schedule()
}mstart初始化了stackguard0 和 stackguard1,mstart1()调用runtime.schedule()
大概步骤:
-
为了保证公平(可能两个goroutine互相切换),一段时间(判断
g.schedtick)会先检查全局队列,如果有,会从全局队列中拿一些goroutine来运行; -
拿不到就接着从本地runq拿
-
再拿不到就要用
findrunnable方法来拿,注意这个方法是阻塞的
// One round of scheduler: find a runnable goroutine and execute it.
// Never returns.
func schedule() {
_g_ := getg()
...
top:
pp := _g_.m.p.ptr()
pp.preempt = false
if sched.gcwaiting != 0 {
gcstopm()
goto top
}
if pp.runSafePointFn != 0 {
runSafePointFn()
}
// Sanity check: if we are spinning, the run queue should be empty.
// Check this before calling checkTimers, as that might call
// goready to put a ready goroutine on the local run queue.
if _g_.m.spinning && (pp.runnext != 0 || pp.runqhead != pp.runqtail) {
throw("schedule: spinning with local work")
}
checkTimers(pp, 0)
var gp *g
var inheritTime bool
...
//先检查全局队列
if gp == nil {
// Check the global runnable queue once in a while to ensure fairness.
// Otherwise two goroutines can completely occupy the local runqueue
// by constantly respawning each other.
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
if gp == nil {
gp, inheritTime = runqget(_g_.m.p.ptr())
// We can see gp != nil here even if the M is spinning,
// if checkTimers added a local goroutine via goready.
}
if gp == nil {
gp, inheritTime = findrunnable() // blocks until work is available
}
}下面是findrunnable的大概流程:
- 从本地,全局队列拿
- 通过
runtime.runqsteal尝试从其他处理器§拿goroutine,这个是随机获取(可以看一下RandomOrder这个结构,其方法保证了公平性)这个过程还可能将其计时器都拿过来(有什么用???针对该goroutine,可以保持时间继续???) - 还找不到,就从netpoll里面拿;
- 最后跑到
runtime.execute方法执行获取的goroutine,做好准备工作后,就通过runtime.gogo(汇编,之前的文章提到过)将goroutine调度到当前线程上;
// Schedules gp to run on the current M.
// If inheritTime is true, gp inherits the remaining time in the
// current time slice. Otherwise, it starts a new time slice.
// Never returns.
//
// Write barriers are allowed because this is called immediately after
// acquiring a P in several places.
//
//go:yeswritebarrierrec
func execute(gp *g, inheritTime bool) {
_g_ := getg()
// Assign gp.m before entering _Grunning so running Gs have an
// M.
_g_.m.curg = gp
gp.m = _g_.m
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + _StackGuard
if !inheritTime {
_g_.m.p.ptr().schedtick++
}
// Check whether the profiler needs to be turned on or off.
hz := sched.profilehz
if _g_.m.profilehz != hz {
setThreadCPUProfiler(hz)
}
if trace.enabled {
// GoSysExit has to happen when we have a P, but before GoStart.
// So we emit it here.
if gp.syscallsp != 0 && gp.sysblocktraced {
traceGoSysExit(gp.sysexitticks)
}
traceGoStart()
}
gogo(&gp.sched)
}有关于gogo函数,这里再次post一次(linux amd64上):
// func gogo(buf *gobuf)
// restore state from Gobuf; longjmp
TEXT runtime·gogo(SB), NOSPLIT, $16-8
MOVQ buf+0(FP), BX // gobuf获取调度信息
MOVQ gobuf_g(BX), DX
MOVQ 0(DX), CX // make sure g != nil
get_tls(CX) //获得当前线程
MOVQ DX, g(CX)
MOVQ gobuf_sp(BX), SP // 1.restore SP 将 runtime.goexit 函数的 PC 恢复到 SP 中
MOVQ gobuf_ret(BX), AX
MOVQ gobuf_ctxt(BX), DX
MOVQ gobuf_bp(BX), BP
MOVQ $0, gobuf_sp(BX) // clear to help garbage collector
MOVQ $0, gobuf_ret(BX)
MOVQ $0, gobuf_ctxt(BX)
MOVQ $0, gobuf_bp(BX)
MOVQ gobuf_pc(BX), BX // 2. 获取待执行函数的程序计数器
JMP BX // 3. 开始执行runtime.gobuf中取出了runtime.goexit的pc和待执行函数的pc,其中:
runtime.goexit的程序计数器被放到了栈 SP 上;- 待执行函数的程序计数器被放到了寄存器 BX 上;
一般来讲,go的函数调用都会使用CALL指令,会先将返回地址加入到栈寄存器SP中,然后跳转到目标函数,当目标函数返回后,会从栈中查找调用的地址,并跳转回调用方继续执行剩下的代码,上面注释的1.2.3就是该过程
接着,在JMP BX命令后,当goroutine运行的函数返回时,就会跳转到runtime.goexit所在位置执行函数:
//????
TEXT runtime·goexit(SB),NOSPLIT,$0-0
CALL runtime·goexit1(SB)
// Finishes execution of the current goroutine.
func goexit1() {
if raceenabled {
racegoend()
}
if trace.enabled {
traceGoEnd()
}
mcall(goexit0)
}我们最终在当前线程的m.g0栈上调用了goexit0函数:
- 该函数会将goroutine设为
_Gdead状态,清除其中字段,移除goroutine和M关联; - 调用
runtime.gfput重新加入处理器goroutine的空闲列表gFree - 但是最后也会再次触发
runtime.schedule,一切再次从头再来成为一个循环;
// goexit continuation on g0.
func goexit0(gp *g) {
_g_ := getg()
casgstatus(gp, _Grunning, _Gdead)
if isSystemGoroutine(gp, false) {
atomic.Xadd(&sched.ngsys, -1)
}
gp.m = nil
locked := gp.lockedm != 0
gp.lockedm = 0
_g_.m.lockedg = 0
gp.preemptStop = false
gp.paniconfault = false
gp._defer = nil // should be true already but just in case.
gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data.
gp.writebuf = nil
gp.waitreason = 0
gp.param = nil
gp.labels = nil
gp.timer = nil
if gcBlackenEnabled != 0 && gp.gcAssistBytes > 0 {
// Flush assist credit to the global pool. This gives
// better information to pacing if the application is
// rapidly creating an exiting goroutines.
scanCredit := int64(gcController.assistWorkPerByte * float64(gp.gcAssistBytes))
atomic.Xaddint64(&gcController.bgScanCredit, scanCredit)
gp.gcAssistBytes = 0
}
dropg()
if GOARCH == "wasm" { // no threads yet on wasm
gfput(_g_.m.p.ptr(), gp)
schedule() // never returns
}
if _g_.m.lockedInt != 0 {
print("invalid m->lockedInt = ", _g_.m.lockedInt, "\n")
throw("internal lockOSThread error")
}
//加入gfree,重用
gfput(_g_.m.p.ptr(), gp)
if locked {
// The goroutine may have locked this thread because
// it put it in an unusual kernel state. Kill it
// rather than returning it to the thread pool.
// Return to mstart, which will release the P and exit
// the thread.
if GOOS != "plan9" { // See golang.org/issue/22227.
gogo(&_g_.m.g0.sched)
} else {
// Clear lockedExt on plan9 since we may end up re-using
// this thread.
_g_.m.lockedExt = 0
}
}
schedule()
}- 上面调用
goexit0是通过mcall,mcall定义如下: ????为什么被重新调度g,fn不可以返回? 因为这里可能进行重新一次调度,选了一个新的goroutine来占用m,详细可以见下面的调度时机 一般来将mcall作用是在goroutine变化时候调用的,在g0栈上执行新的函数
// mcall switches from the g to the g0 stack and invokes fn(g),
// where g is the goroutine that made the call.
// mcall saves g's current PC/SP in g->sched so that it can be restored later.
// It is up to fn to arrange for that later execution, typically by recording
// g in a data structure, causing something to call ready(g) later.
// mcall returns to the original goroutine g later, when g has been rescheduled.
//????
// fn must not return at all; typically it ends by calling schedule, to let the m
// run other goroutines.
//
// mcall can only be called from g stacks (not g0, not gsignal).
// mcall只能在g的栈被调用;
// This must NOT be go:noescape: if fn is a stack-allocated closure,
// fn puts g on a run queue, and g executes before fn returns, the
// closure will be invalidated while it is still executing.
func mcall(fn func(*g))综上,整个goroutine如果无抢占情况下的:调度循环如图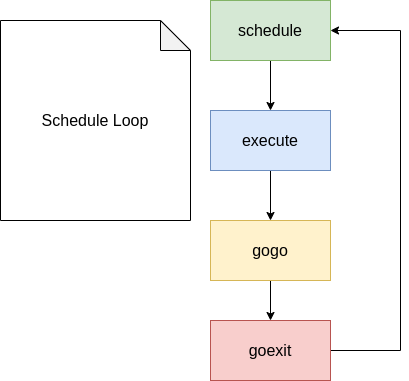
调度时机
可以看这幅图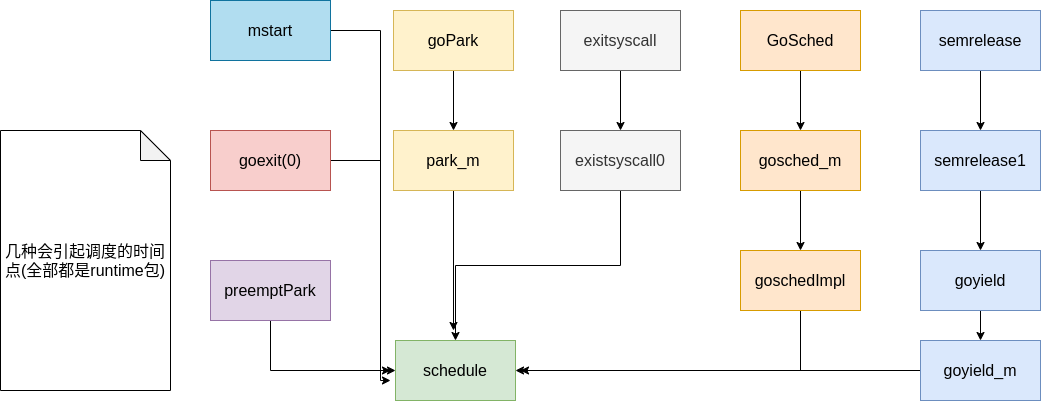 其实就是看一下哪里调用了
其实就是看一下哪里调用了runtime.schedule方法:
主动挂起
gopark方法,由channel操作、sleep、netpoll_block、gc、select等待
runtime.gopark->runtime.park_m
runtime.gopark这个方法会将当前goroutine暂停,被暂停的任务不会放回runq:
// Puts the current goroutine into a waiting state and calls unlockf.
// If unlockf returns false, the goroutine is resumed.
// unlockf must not access this G's stack, as it may be moved between
// the call to gopark and the call to unlockf.
// Reason explains why the goroutine has been parked.
// It is displayed in stack traces and heap dumps.
// Reasons should be unique and descriptive.
// Do not re-use reasons, add new ones.
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceEv byte, traceskip int) {
if reason != waitReasonSleep {
checkTimeouts() // timeouts may expire while two goroutines keep the scheduler busy
}
mp := acquirem()
gp := mp.curg
status := readgstatus(gp)
if status != _Grunning && status != _Gscanrunning {
throw("gopark: bad g status")
}
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waittraceev = traceEv
mp.waittraceskip = traceskip
releasem(mp)
// can't do anything that might move the G between Ms here.
mcall(park_m)
}runtime.park_m:
- 将状态变成
_Gwaiting - 然后
dropg将当前用户goroutinem.curg与m断开 - 此时就可以调用
schedule触发新一轮调度
// park continuation on g0.
func park_m(gp *g) {
_g_ := getg()
if trace.enabled {
traceGoPark(_g_.m.waittraceev, _g_.m.waittraceskip)
}
casgstatus(gp, _Grunning, _Gwaiting)
dropg()
if fn := _g_.m.waitunlockf; fn != nil {
ok := fn(gp, _g_.m.waitlock)
_g_.m.waitunlockf = nil
_g_.m.waitlock = nil
if !ok {
if trace.enabled {
traceGoUnpark(gp, 2)
}
casgstatus(gp, _Gwaiting, _Grunnable)
execute(gp, true) // Schedule it back, never returns.
}
}
schedule()
}- 在goroutine等待的条件满足后(???哪里满足,位置???),会调用
runtime.goready将之前gopark进入_Gwaiting状态的goroutine唤醒; runtime.ready将goroutine状态从_Gwaiting或者_Gscanwaiting变为_Grunnable,并进入runq
func goready(gp *g, traceskip int) {
systemstack(func() {
ready(gp, traceskip, true)
})
}
// Mark gp ready to run.
func ready(gp *g, traceskip int, next bool) {
if trace.enabled {
traceGoUnpark(gp, traceskip)
}
status := readgstatus(gp)
// Mark runnable.
_g_ := getg()
mp := acquirem() // disable preemption because it can be holding p in a local var
if status&^_Gscan != _Gwaiting {
dumpgstatus(gp)
throw("bad g->status in ready")
}
// status is Gwaiting or Gscanwaiting, make Grunnable and put on runq
casgstatus(gp, _Gwaiting, _Grunnable)
runqput(_g_.m.p.ptr(), gp, next)
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 {
wakep()
}
releasem(mp)
}系统调用
这部分代码主要是汇编组成:
syscall.Syscall
同样是linux amd64:
//
// System call support for AMD64, Darwin
//
// Trap # in AX, args in DI SI DX, return in AX DX
// func Syscall(trap, a1, a2, a3 uintptr) (r1, r2 uintptr, err Errno);
TEXT ·Syscall(SB),NOSPLIT,$0-56
CALL runtime·entersyscall(SB)
MOVQ a1+8(FP), DI
MOVQ a2+16(FP), SI
MOVQ a3+24(FP), DX
MOVQ trap+0(FP), AX // syscall entry
ADDQ $0x2000000, AX
SYSCALL
JCC ok
MOVQ $-1, r1+32(FP)
MOVQ $0, r2+40(FP)
MOVQ AX, err+48(FP)
CALL runtime·exitsyscall(SB)
RET
ok:
MOVQ AX, r1+32(FP)
MOVQ DX, r2+40(FP)
MOVQ $0, err+48(FP)
CALL runtime·exitsyscall(SB)
RET注意到runtime.entersyscall,实际就是提供syscall前保存pc、sp,以便恢复;
然后调用reentersyscall:
- 首先会先
m.lock++,不让抢占(但是这里可能会造成goroutine状态atomicstatus=Gsyscall与g.sched调度器中的状态不一致,不可以让gc发现???如何???),会造成内存不一致??? - 不可以调用任何会造成split stack的函数,因为其调用了
gosave:其会使g.sched指向调用者的栈(如果split,就不知道指去哪里了)以便立即返回 save(pc, sp)保存当前pc和sp- 更新goroutine状态为
_Gsyscall - 分离goroutine和P,并将P状态更新为
_Psyscall,这时候会陷入syscall,要等待返回; - 释放锁
m.lock--,可能就有其他goroutine来抢P资源了
// Standard syscall entry used by the go syscall library and normal cgo calls.
//
// This is exported via linkname to assembly in the syscall package.
//
//go:nosplit
//go:linkname entersyscall
func entersyscall() {
reentersyscall(getcallerpc(), getcallersp())
}
// The goroutine g is about to enter a system call.
// Record that it's not using the cpu anymore.
// This is called only from the go syscall library and cgocall,
// not from the low-level system calls used by the runtime.
//
// Entersyscall cannot split the stack: the gosave must
// make g->sched refer to the caller's stack segment, because
// entersyscall is going to return immediately after.
//
// Nothing entersyscall calls can split the stack either.
// We cannot safely move the stack during an active call to syscall,
// because we do not know which of the uintptr arguments are
// really pointers (back into the stack).
// In practice, this means that we make the fast path run through
// entersyscall doing no-split things, and the slow path has to use systemstack
// to run bigger things on the system stack.
//
// reentersyscall is the entry point used by cgo callbacks, where explicitly
// saved SP and PC are restored. This is needed when exitsyscall will be called
// from a function further up in the call stack than the parent, as g->syscallsp
// must always point to a valid stack frame. entersyscall below is the normal
// entry point for syscalls, which obtains the SP and PC from the caller.
//
// Syscall tracing:
// At the start of a syscall we emit traceGoSysCall to capture the stack trace.
// If the syscall does not block, that is it, we do not emit any other events.
// If the syscall blocks (that is, P is retaken), retaker emits traceGoSysBlock;
// when syscall returns we emit traceGoSysExit and when the goroutine starts running
// (potentially instantly, if exitsyscallfast returns true) we emit traceGoStart.
// To ensure that traceGoSysExit is emitted strictly after traceGoSysBlock,
// we remember current value of syscalltick in m (_g_.m.syscalltick = _g_.m.p.ptr().syscalltick),
// whoever emits traceGoSysBlock increments p.syscalltick afterwards;
// and we wait for the increment before emitting traceGoSysExit.
// Note that the increment is done even if tracing is not enabled,
// because tracing can be enabled in the middle of syscall. We don't want the wait to hang.
//
//go:nosplit
func reentersyscall(pc, sp uintptr) {
_g_ := getg()
// Disable preemption because during this function g is in Gsyscall status,
// but can have inconsistent g->sched, do not let GC observe it.
_g_.m.locks++
// Entersyscall must not call any function that might split/grow the stack.
// (See details in comment above.)
// Catch calls that might, by replacing the stack guard with something that
// will trip any stack check and leaving a flag to tell newstack to die.
_g_.stackguard0 = stackPreempt
_g_.throwsplit = true
// Leave SP around for GC and traceback.
save(pc, sp)
_g_.syscallsp = sp
_g_.syscallpc = pc
casgstatus(_g_, _Grunning, _Gsyscall)
if _g_.syscallsp < _g_.stack.lo || _g_.stack.hi < _g_.syscallsp {
systemstack(func() {
print("entersyscall inconsistent ", hex(_g_.syscallsp), " [", hex(_g_.stack.lo), ",", hex(_g_.stack.hi), "]\n")
throw("entersyscall")
})
}
if trace.enabled {
systemstack(traceGoSysCall)
// systemstack itself clobbers g.sched.{pc,sp} and we might
// need them later when the G is genuinely blocked in a
// syscall
save(pc, sp)
}
if atomic.Load(&sched.sysmonwait) != 0 {
systemstack(entersyscall_sysmon)
save(pc, sp)
}
if _g_.m.p.ptr().runSafePointFn != 0 {
// runSafePointFn may stack split if run on this stack
systemstack(runSafePointFn)
save(pc, sp)
}
_g_.m.syscalltick = _g_.m.p.ptr().syscalltick
_g_.sysblocktraced = true
_g_.m.mcache = nil
pp := _g_.m.p.ptr()
pp.m = 0
_g_.m.oldp.set(pp)
_g_.m.p = 0
atomic.Store(&pp.status, _Psyscall)
if sched.gcwaiting != 0 {
systemstack(entersyscall_gcwait)
save(pc, sp)
}
_g_.m.locks--
}runtime.exitsyscall则从syscall中恢复,比较复杂:
- 同样要锁住
m.locks++,不给抢占先, - 写屏障不能用,p可能在syscall过程中被窃取(即当前p不是syscall前的p)
- 会走到两个路径
exitsyscallfast或者通过mcall(切换到调度器的goroutine)调用exitsyscall0进行退出
// The goroutine g exited its system call.
// Arrange for it to run on a cpu again.
// This is called only from the go syscall library, not
// from the low-level system calls used by the runtime.
//
// Write barriers are not allowed because our P may have been stolen.
//
// This is exported via linkname to assembly in the syscall package.
//
//go:nosplit
//go:nowritebarrierrec
//go:linkname exitsyscall
func exitsyscall() {
_g_ := getg()
_g_.m.locks++ // see comment in entersyscall
if getcallersp() > _g_.syscallsp {
throw("exitsyscall: syscall frame is no longer valid")
}
_g_.waitsince = 0
oldp := _g_.m.oldp.ptr()
_g_.m.oldp = 0
if exitsyscallfast(oldp) {
if _g_.m.mcache == nil {
throw("lost mcache")
}
if trace.enabled {
if oldp != _g_.m.p.ptr() || _g_.m.syscalltick != _g_.m.p.ptr().syscalltick {
systemstack(traceGoStart)
}
}
// There's a cpu for us, so we can run.
_g_.m.p.ptr().syscalltick++
// We need to cas the status and scan before resuming...
casgstatus(_g_, _Gsyscall, _Grunning)
// Garbage collector isn't running (since we are),
// so okay to clear syscallsp.
_g_.syscallsp = 0
_g_.m.locks--
if _g_.preempt {
// restore the preemption request in case we've cleared it in newstack
_g_.stackguard0 = stackPreempt
} else {
// otherwise restore the real _StackGuard, we've spoiled it in entersyscall/entersyscallblock
_g_.stackguard0 = _g_.stack.lo + _StackGuard
}
_g_.throwsplit = false
if sched.disable.user && !schedEnabled(_g_) {
// Scheduling of this goroutine is disabled.
Gosched()
}
return
}
_g_.sysexitticks = 0
if trace.enabled {
// Wait till traceGoSysBlock event is emitted.
// This ensures consistency of the trace (the goroutine is started after it is blocked).
for oldp != nil && oldp.syscalltick == _g_.m.syscalltick {
osyield()
}
// We can't trace syscall exit right now because we don't have a P.
// Tracing code can invoke write barriers that cannot run without a P.
// So instead we remember the syscall exit time and emit the event
// in execute when we have a P.
_g_.sysexitticks = cputicks()
}
_g_.m.locks--
// Call the scheduler.
mcall(exitsyscall0)
if _g_.m.mcache == nil {
throw("lost mcache")
}
// Scheduler returned, so we're allowed to run now.
// Delete the syscallsp information that we left for
// the garbage collector during the system call.
// Must wait until now because until gosched returns
// we don't know for sure that the garbage collector
// is not running.
_g_.syscallsp = 0
_g_.m.p.ptr().syscalltick++
_g_.throwsplit = false
}针对exitsyscallfast:
- 如果goroutine处于
_Psyscall状态,尝试用wirep将其与goroutine与之前旧的g.m.oldP(就是syscall之前会保存进来的)相连接; - 如果全局调度器中有其他的空闲p,就会在
systemstack下调用exitsyscallfast_pidle来获取p,其中exitsyscallfast_pidle方法会使用acquirep调用空闲的p来接管当前goroutine
//go:nosplit
func exitsyscallfast(oldp *p) bool {
_g_ := getg()
// Freezetheworld sets stopwait but does not retake P's.
if sched.stopwait == freezeStopWait {
return false
}
// Try to re-acquire the last P.
if oldp != nil && oldp.status == _Psyscall && atomic.Cas(&oldp.status, _Psyscall, _Pidle) {
// There's a cpu for us, so we can run.
wirep(oldp)
exitsyscallfast_reacquired()
return true
}
// Try to get any other idle P.
if sched.pidle != 0 {
var ok bool
systemstack(func() {
ok = exitsyscallfast_pidle()
if ok && trace.enabled {
if oldp != nil {
// Wait till traceGoSysBlock event is emitted.
// This ensures consistency of the trace (the goroutine is started after it is blocked).
for oldp.syscalltick == _g_.m.syscalltick {
osyield()
}
}
traceGoSysExit(0)
}
})
if ok {
return true
}
}
return false
}另一个exitsyscall0(较慢):
- 首先会将
Gsyscall状态设为Grunnable - 然后
dropg断开g与P的联系; - 然后锁住全局调度器,
pidleget()获得空闲p,然这个p接管goroutine - 如果
pidleget()无法获得p,则将当前g放入全局的sched.runq,等待调度器; - 解锁,下面就是一系列调度;
// exitsyscall slow path on g0.
// Failed to acquire P, enqueue gp as runnable.
//
//go:nowritebarrierrec
func exitsyscall0(gp *g) {
_g_ := getg()
casgstatus(gp, _Gsyscall, _Grunnable)
dropg()
lock(&sched.lock)
var _p_ *p
if schedEnabled(_g_) {
_p_ = pidleget()
}
if _p_ == nil {
globrunqput(gp)
} else if atomic.Load(&sched.sysmonwait) != 0 {
atomic.Store(&sched.sysmonwait, 0)
notewakeup(&sched.sysmonnote)
}
unlock(&sched.lock)
if _p_ != nil {
//将p与当前m联系起来
acquirep(_p_)
//开始在当前M开始运行传入的gp(goroutine)
execute(gp, false) // Never returns.
}
if _g_.m.lockedg != 0 {
// Wait until another thread schedules gp and so m again.
stoplockedm()
execute(gp, false) // Never returns.
}
stopm()
schedule() // Never returns.
}协作式调度
协作式调度主要是依靠runtime.GoSched()主动让出P,但该函数无法挂起goroutine,调度器会自动调度当前的goroutine???
- 会更新当前g状态
Grunning到Grunnable - 断开g与当前P的状态
- 将当前g放入全局
sched.runq - 开始调度
//go:nosplit
// Gosched yields the processor, allowing other goroutines to run. It does not
// suspend the current goroutine, so execution resumes automatically.
func Gosched() {
checkTimeouts()
mcall(gosched_m)
}
// Gosched continuation on g0.
func gosched_m(gp *g) {
if trace.enabled {
traceGoSched()
}
goschedImpl(gp)
}
func goschedImpl(gp *g) {
status := readgstatus(gp)
if status&^_Gscan != _Grunning {
dumpgstatus(gp)
throw("bad g status")
}
casgstatus(gp, _Grunning, _Grunnable)
dropg()
lock(&sched.lock)
globrunqput(gp)
unlock(&sched.lock)
schedule()
}sysmon
主要对运行时间过长的,强行让出
p中的schedtick 和 schedwhen与当前时间计算,运算出是否超时,要让出
runtime.retake方法中的runtime.preemptone进行异步抢占:
retake()方法会先锁住全局allp,注意这里一定要在stw条件下,否则不成功
- 注意在
syscall中,preemptone()无法工作,因为此时,无P与M关联(syscall会让出p)
func sysmon() {
...
// retake P's blocked in syscalls
// and preempt long running G's
if retake(now) != 0 {
idle = 0
} else {
idle++
}
...
}
func retake(now int64) uint32 {
//锁住全局allp,不让改变
lock(&allpLock)
for i := 0; i < len(allp); i++ {
...
if s == _Prunning || s == _Psyscall {
// Preempt G if it's running for too long.
t := int64(_p_.schedtick)
//G对应的schedtick跟监控的不一致,则需要重新更新一些sched的数值
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
//forcePreemptNS=10ms
// 如果超过了10ms就需要进行抢占了
preemptone(_p_)
// In case of syscall, preemptone() doesn't
// work, because there is no M wired to P.
sysretake = true
}
}
...
}
}在符合条件下会调用preemptone():
- 该方法是尽力模型,有可能错误地通知goroutine;
- 即使它正确通知了goroutine,goroutine也可能会忽视请求如果该goroutine同时在执行
newstack函数(runtime·morestack会call这个函数,用于栈扩容) 不需要锁(上面allp已经锁住)- 真正的抢占会发生在未来的某个时间点,当
gp.status!=Grunnning时会被标记出
// Tell the goroutine running on processor P to stop.
// This function is purely best-effort. It can incorrectly fail to inform the
// goroutine. It can send inform the wrong goroutine. Even if it informs the
// correct goroutine, that goroutine might ignore the request if it is
// simultaneously executing newstack.
// No lock needs to be held.
// Returns true if preemption request was issued.
// The actual preemption will happen at some point in the future
// and will be indicated by the gp->status no longer being
// Grunning
func preemptone(_p_ *p) bool {
mp := _p_.m.ptr()
if mp == nil || mp == getg().m {
return false
}
gp := mp.curg
if gp == nil || gp == mp.g0 {
return false
}
//这个同stackguard0 = stackPreempt属性其实一样
gp.preempt = true
// Every call in a go routine checks for stack overflow by
// comparing the current stack pointer to gp->stackguard0.
// Setting gp->stackguard0 to StackPreempt folds
// preemption into the normal stack overflow check.
//在一个goroutine中检查栈溢出都是靠对比 现在栈指针 和 gp.stackguard0, 设置gp.stackguard0=stackPreempt 就是等于 将抢占放入一般的栈溢出检查中????;
gp.stackguard0 = stackPreempt
// Request an async preemption of this P.
if preemptMSupported && debug.asyncpreemptoff == 0 {
_p_.preempt = true
preemptM(mp)
}
return true
}- Channel,mutex之类同步操作发生阻塞
- time.sleep
- 主动调用runtime.GoSched()
- 网络IO阻塞
- gc
- 运行过久或者系统调用过久
OS线程锁
runtime.LockOSThread //todo
死锁检测和终止
//todo??? 当所有P是idle的时候进行检测(全局idle P的原子计数)
旋转态->不旋态的转换中, 可能和创建一个新的goroutine和创建一部分或其他需要unpark的工作线程 的时候发生竞态条件 如果转换和创建都失败,我们就可以以半静态cpu未充分利用结束; goroutine 准备步骤是:提交一个goroutine去local queue,store-style memory 屏障,检查sched.nmspinning
不旋态->旋转态是: 减少nmspinning,store-style memory 屏障,检查新的work的所有per-P work queue 而且以上都不适用于global run queue
协作式抢占
retake() 调用runtime.preemptone()将被抢占的G的stackguard0 设为stackPreempt,
被设置标志的G下一次进行函数调用的时候,检查栈空间失败。然后会触发morestack() (汇编代码,asm_xxx.s)
然后进行一连串的函数调用
大概流程
morestack()–> newstack()–> gopreempt_m() --> goschedImpl() --> schedule()
补充:
网上的经验(为什么呢???):
这个goroutine类似于线程池管理(c++线程池原理相似),
- 遇到阻塞的情况,怎么扩展进程池,使其不会因为任务阻塞或者同步独占线程
-
goroutine类似green threads(Green threads),是application自己维护的执行过程;很多goroutines实际上被有限个操作系统管理的threads执行;
-
goroutine的调度往往发生在I/O和系统调用的时候。如果创建的goroutines都是跑for循环做纯计算(没有I/O),那就需要我们自己时不常的调用 runtime.Gosched(),否则那几个在thread上跑的goroutines会霸占着threads,不让其他goroutines有机会跑起来;
-
用户代码造成的协程同步造成的阻塞,只是切换(gopark)协程,而不是阻塞线程,m和p仍结合,去寻找新的可执行的g;
-
上层封装了epoll,网络fd会设置成NonBlocking模式,返回EAGAIN则gopark当前goroutine,在m调度,sysmon中,gc start the world等阶段均会poll出ready的goroutine进行运行或者添加到全局runq中
一些小细节 代码经常发现一些编辑器生成的//go:nosplit字样
The //go:nosplit directive specifies that the next function declared in the file must not include a stack overflow check. This is most commonly used by low-level runtime sources invoked at times when it is unsafe for the calling goroutine to be preempted.
大意即为这个生成函数不能含有检查栈溢出的代码,即会跳过栈溢出检查(why???个人认为是设计问题,就不允许有检查栈移除代码),有时goroutine要被抢占陷入不安全情况时,被底层runtime调用
SystemStack
SystemStack(fn func()) 系统栈 被不同地方调用会有不同的表现方式:
-
直接调用fn并返回 需要满足:
-
被 单个线程的g0 stack调用 或
-
被信号处理的栈(gsignal)调用,m中有个gsinal字段 ???
-
-
否则,都从一个普通的goroutine的有限的stack中调用
表现: 会先切去线程的栈,调用fn,然后切回来该goroutine的栈
// systemstack runs fn on a system stack.
// If systemstack is called from the per-OS-thread (g0) stack, or
// if systemstack is called from the signal handling (gsignal) stack,
// systemstack calls fn directly and returns.
// Otherwise, systemstack is being called from the limited stack
// of an ordinary goroutine. In this case, systemstack switches
// to the per-OS-thread stack, calls fn, and switches back.
// It is common to use a func literal as the argument, in order
// to share inputs and outputs with the code around the call
// to system stack:
//
// ... set up y ...
// systemstack(func() {
// x = bigcall(y)
// })
// ... use x ...
//
//go:noescape
func systemstack(fn func())一个大概的go程序启动流程
golang注释中有大概写明:
// The bootstrap sequence is:
//
// call osinit
// call schedinit
// make & queue new G
// call runtime·mstart
// The new G calls runtime·main.
go程序的入口点是runtime.rt0_go, 流程是:
- 分配栈空间, 需要2个本地变量+2个函数参数, 然后向8对齐
把传入的argc和argv保存到栈上(rdx寄存器通常用作上下文存储)
更新g0中的stackguard的值, stackguard用于检测栈空间是否不足, 需要分配新的栈空间(栈扩展会申请多一块栈空间并把现在的复制过去)
获取当前cpu的信息并保存到各个全局变量
调用_cgo_init如果函数存在
- 初始化当前线程的TLS(thread-local-storage), 设置FS寄存器为m0.tls+8(获取时会-8) 这里跟SP寄存器有关(伪的SP寄存器的地址 = 硬件SP寄存器+8,64位机)
测试TLS是否工作
设置g0到TLS中, 表示当前的g是g0
设置m0.g0 = g0
设置g0.m = m0
特殊的m0和g0
-
M0是启动程序后的编号为 0 的主线程,这个 M 对应的实例会在全局变量runtime.m0中,不需要在heap上分配,M0负责执行初始化操作和启动第一个 G, 在之后 M0 就和其他的 M 一样了。 -
G0是每次启动一个 M 都会第一个创建的 gourtine,G0仅用于负责调度的 G(作用);G0不指向任何可执行的函数,每个 M 都会有一个自己的G0。在调度或系统调用时会使用 G0 的栈空间(栈空间是一定的,Unix一般是8MB),全局变量的G0是M0的G0(这种一般指sysmon,垃圾回收器等,注意调度器本身属于第三种goroutine,不是g0,也不是普通的goroutine)
- 调用runtime.check做一些检查
调用runtime.args保存传入的argc和argv到全局变量
调用runtime.osinit根据系统执行不同的初始化
这里(linux x64)设置了全局变量ncpu等于cpu核心数量
- 调用**runtime.schedinit()**执行共同的初始化
这里的处理比较多:
-
首先会调用raceinit()检查race condition
-
然后进接这tracebackinit()和moduledateverify(),分别为一些变量提前初始化和包的验证
func tracebackinit() {
// Go variable initialization happens late during runtime startup.
// Instead of initializing the variables above in the declarations,
// schedinit calls this function so that the variables are
// initialized and available earlier in the startup sequence.
skipPC = funcPC(skipPleaseUseCallersFrames)
}- 会初始化栈空间分配器(stackinit)
func stackinit() {
//// Per-P, per order stack segment cache size.
//_StackCacheSize = 32 * 1024
// stack的分段大小一定要是pagesize的倍数(容易理解,方便对齐)
//_PageShift = 13
//_PageSize = 1 << _PageShift = 8192
//_PageMask = _PageSize - 1
if _StackCacheSize&_PageMask != 0 {
throw("cache size must be a multiple of page size")
}
//stackpool就是一个span的双向链表
for i := range stackpool {
stackpool[i].init()
}
// stackLarge的free是一个list , 大小为 log_2(s.npages)
for i := range stackLarge.free {
stackLarge.free[i].init()
}
}这里插入一副盗借来的 更加明确发现一些奇怪的特点
更加明确发现一些奇怪的特点
-
mallocinit()
- 这个最主要是检查page,huge page大小是不是2的倍数以及是不是大于最小页大小(4KB)
- 然后就初始化 heap,在memManage 那篇文章有讲到,会初始化多个fixalloc,包括treap,span,cache,specialfinalizer,specialprofile,arenaHint 还有getg()获得当前g的指针,以及初始化当前mcache(allocmcache())
- 创建初始化的arena区域(即是heap)的增长规则,注意在64bit机器中,其做了一些优化:
从中间空间开始分配,如上面的图一样,
- 可以更加容易地增长连续空间
- 使其更加容易debug
- 为了gccgo区别于其他数据
- UTF8编码
-
mcommoninit(g.m),这里是一些公共初始化 主要对_g_.m即自己的m进行一些初始化
-
按cpu核心数量或GOMAXPROCS的值生成P(cpuinit)
cpuinit() // must run before alginit- alginit
alginit() // maps must not be used before this call- 生成P的处理在procresize中
更改了P的数目,期间stop the world并锁住sched,返回本地的所有p
func schedinit(){
...
sched.lastpoll = uint64(nanotime())
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
...
}
// Change number of processors. The world is stopped, sched is locked.
// gcworkbufs are not being modified by either the GC or
// the write barrier code.
// Returns list of Ps with local work, they need to be scheduled by the caller.
func procresize(nprocs int32) *p { ... }-
调用runtime.newproc创建一个新的goroutine, 指向的是runtime.main runtime.newproc这个函数在创建普通的goroutine时也会使用;
-
调用runtime·mstart启动m0
- 启动后m0会不断从运行队列获取G并运行, runtime.mstart调用后不会返回
- runtime.mstart这个函数是m的入口点(不仅仅是m0), 在下面的"调度器的实现"中会详细讲解
runtime.main之后
第一个被调度的G会运行runtime.main, 流程是:
标记主函数已调用, 设置mainStarted = true
启动一个新的M执行sysmon函数, 这个函数会监控全局的状态并对运行时间过长的G进行抢占
要求G必须在当前M(系统主线程)上执行
调用runtime_init函数
调用gcenable函数
调用main.init函数, 如果函数存在
不再要求G必须在当前M上运行
如果程序是作为c的类库编译的, 在这里返回
调用main.main函数
如果当前发生了panic, 则等待panic处理
调用exit(0)退出程序
Defer函数
平常用的
func do(){
defer done()
}其结构在 runtime2.go 结构体g中
type g struct{
goid int64
...
//其结构有些在stack中有些在heap中,但是逻辑上都属于stack,所以写屏障是没有必要的;
_defer *defer{
siz int32 // includes both arguments and results
started bool
heap bool
sp uintptr // sp at time of defer
pc uintptr
fn *funcval //调用的函数
_panic *_panic // panic that is running defer
link *_defer
}
...
}本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!