Notes about Zookeeper
占坑
其名字的来源就是Yahoo的项目组,因为其内部很多以动物为名,所以一种可以方便管理多个服务的程序zookeeper就出现了…
首先,Zookeeper是一个分布式的程序,所以很自然就会采用分布式地部署(集群);
提供的功能说大不大:
- 管理用户程序提交的数据
- 节点监听服务(服务治理,调度等)
常见的概念
Session
顾名思义,指server和client端之间的一个连接,这个是一个TCP的长连接;
开始时,每个client都会获得一个sessionId,这个sessionID一定要保持 全局唯一,因为下面很多选举以及其他功能都要靠该字段保证
ZNode
zookeeper中的节点分为两类:
- 即是机器,机器节点
- 数据节点ZNode
其中数据节点ZNode的数据结构其实是一种树状结构,由斜杠 / 进行分割的路径就是一个ZNode,比如/spls/hols, 每个节点都有保存自己的信息,还有一系列metadata
而ZNode又可以分为持久节点(PERSISTENT)和临时节点(EPHEMERAL);
顾名思义,持久指的是除非被进行显式移除操作,否则会一直存在zookeeper中, 而临时节点一般是与session绑定,一旦session过期或者失效就会立即被移除;
这里还有另外两种ZNode:
- 持久顺序节点(PERSISTENT_SEQUENTIAL), 同持久节点差不多,额外允许一个SEQUENTIAL参数(int),由父节点维护的自增数字,会加在当前节点后面;
- 临时顺序节点(EPHEMERAL_SEQUENTIAL), 同临时节点差不多只不过就是增加了一个顺序参数;
ZAB协议
这里就是重头戏了!!!
ZAB协议是专门给zookeeper设计的支持崩溃回复的原子广播协议,其包括两种模式:
- 崩溃模式
- 消息广播
消息广播
这个是最基本的一个模式,实际上同2PC十分接近: 步骤大概如下:
- Leader将client的request转化成一个Proposal
- Leader为每一个Follower准备了一个FIFO队列,并把proposal发送到队列上;
- Follower会从队列头部拿出proposal,然后将ACK放入回队列中,
- Leader如果从队列收到follower一半以上ACK反馈,就会将commit又发回到队列中
- Follower继续从队列头部拿数据,拿到commit命令就完成;
但是这里每一步中leader都可能崩溃(毕竟Leader压力也大) 接下来就要进入到崩溃模式
崩溃模式
大家都要恰饭,不可能等leader自己好起来,所以就要选举一个新的leader,这里很自然就涉及两个操作
- 选举新的leader
- 新的leader要继续之前的工作
选举新的leader
这里首先可以描述几个状态:
- Looking状态
- following状态
- Leading状态
比较容易理解,至于选举的时机,无疑就是在 初始化程序的时候 和 leader崩溃后
之前的文章有写过raft等分布式协议,ZAB也是一个有选举的协议, 所以一定有:
任命周期
election epoch,对应于raft的term,一般分布式协议都有以消息标记一个事件,这种事件会同其他事件区分开,而区分的方法很多就是使用了时间戳; ZAB中,每个消息都赋予了一个zxid,zxid全局唯一;
zxid由两部分组成:
- 高32位为epoch
- 低32位为epoch内自增id,每次epoch更新,低32位自增id就会归0 (万一一直不更新???)
log
ZAB和raft一样都是基于复制状态机(replicated state machine)来记录不同机器的行为,其都使用log来记录 一般有两种方式:
- 所有日志取最新的一条 (raft,ZAB)
- 所有已提交的最新的一条
Zookeeper: peerEpoch大的优先,然后到zxid大的优先 Raft: Term大的优先,再到entry的index大的优先
但是这里Zookeeper与raft有一些不同的是:
Zookeeper会将两个比较分为两轮,而Raft会结合到一起进行判断 (???)
但是关于log的最新值问题之前已经讨论过,raft中可能会有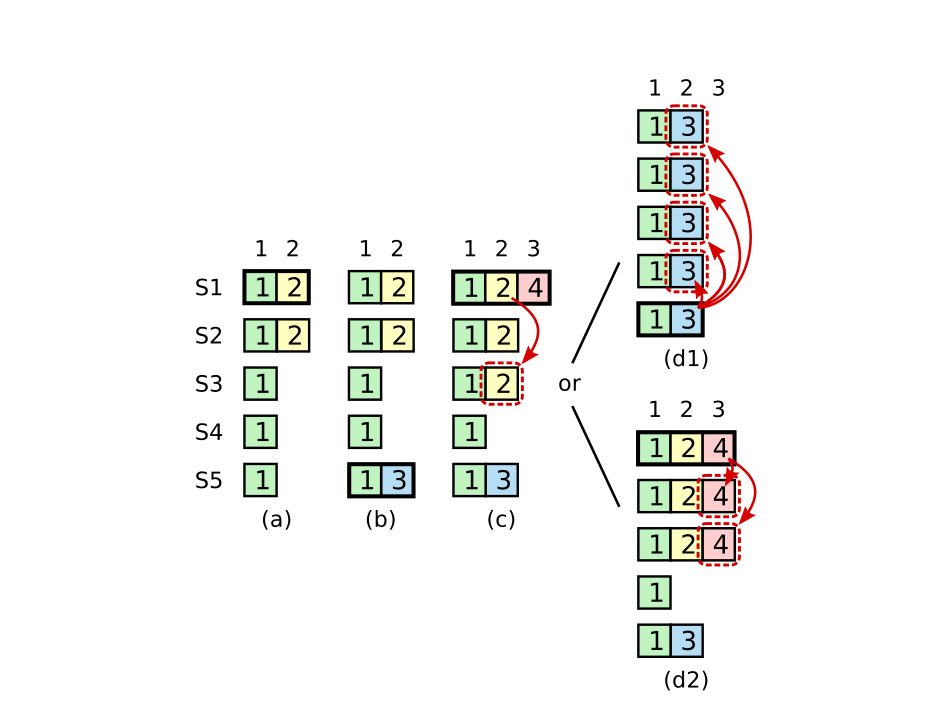
(a)中S1是leader,且部分复制到log entry到其他机子,暂时只复制到S2;
(b)S1崩溃,S5在接收到 S3,S4以及自己的vote 选举成功,进入新的term,并接受了一个不同的entry(index 2)
©接着S5崩溃,S1重启,被选举为leader,然后继续复制状态,在这个时候term 2 的log已经被大多数的机子复制,但是未commit,这个时候接下来就可能有两种情况:
-
(d1) 如果S1再次崩溃,S5会再次被选举(接到S2,S3,S4)的vote,然后用自己term3的entry覆盖所有的entry(即使在©的情况下,S1的log entry已经被大部分接收,但未commit,也可能会被覆盖)
-
(d2) 然而如果S1在崩溃前复制自己term的entry到一半以上的机子,这时候根据规则就会commit(因为S5是不会赢得选举); 这个就是理想的状态,为了解决(d1)覆盖问题,raft 不允许 commit 前一个term的log entry;
选举出来的leader可能不包含已经提交过的log,raft针对这个做出了一个限制:
- log的提交不能直接提交之前term的已经过半的entry,意思是如果遇到这些term过半的entry就视为未提交的 其原因就是,raft选举永远是单向的
This means that log entries only flow in one direction, from leaders to followers, and leaders never overwrite existing entries in their logs
解决这个问题,都很明显,双向确认即可, Zookeeper即是采用该手段,每次选举完leader后,都会更新follower的log,所以每一轮大家的数据都会保持一致(???具体代码)
投票次数
Raft每个server每一轮只投一次,一般来讲哪些candidate先RequestVote就会先获得投票,这样的结果是可能会造成所有candidate都没有收到过半的票然后重试; raft解决这个方法就是随机 + - 时间来发起投票;
Zookeeper每个server在某个electionEpoch内,可以投多次票,只要遇到更大的票就更新,然后再分发新的票给所有server,这样不会造成raft投票不成功的现象,同时也可以选出含有log更多的server(???),但是明显时间就会花费更多;
重启server加入集群中
Raft启动后,会收到leader的appendEntries; Zookeeper的server启动后,会向所有server发送投票通知,这个时候收到处在LOOKING,FOLLOWING的server的投票, 则该server放弃自己的投票(????)
缺点
-
zk 在选举的过程中的为了保证最终一致性是不能写入和读取的,也就是说 zk 在选举过程中是不可用的,所以从 cap 理论来说 zk 属于 cp,而注册中心往往的要求的是 ap;
-
同时,zk 写入只能在 leader 节点操作,当有大量服务提供者同时启动时,有可能造成 leader 节点负载过大,从而死机,然后重新选举,死机,形成恶性循环,所以 zk 并不太适合作为注册中心;
.nethttp://jiurl.nease
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!